The Global Communication Crisis Every Enterprise Faces
Every day, global enterprises face a monumental challenge. A multinational financial services company headquartered in New York receives customer inquiries in 37 languages. A healthcare organization serves immigrant communities across multiple continents. A software company supports users in 150 countries. An e-commerce platform manages product descriptions, customer reviews, and support tickets across every major language.
Today, most enterprises handle this crisis the same way they have for decades: hiring expensive human translators. A single document translation costs between $0.15 and $0.35 per word. A 5,000 word legal contract costs $750 to $1,750 to translate professionally. A customer service department hiring multilingual support staff increases payroll costs by 25-35%. Global enterprises collectively spend $50 billion annually on professional translation services.
In 2026, machine translation has matured from experimental research to production-critical technology that directly impacts business outcomes. Leading enterprises report remarkable outcomes:
The convergence of three forces created perfect conditions for machine translation adoption to explode. First, neural machine translation models trained on hundreds of billions of sentence pairs now outperform human translators on specific language pairs. Second, large language models like GPT-4 brought unprecedented translation quality without language-specific training. Third, cloud providers made industrial-strength translation APIs available to every developer through simple API calls.
Machine translation is no longer nice-to-have infrastructure. It is becoming table stakes for any enterprise operating across language boundaries.
Understanding Machine Translation: The Core Concept
Machine translation is the automated conversion of text or speech from one natural language to another language using artificial intelligence. Think of it as teaching a computer system to do what professional translators do, but at machine speed and scale.
Imagine you are a translator reading an English document about a business acquisition. You read the entire document to understand context. You recognize that “acquisition” means “purchasing another company” not “acquiring an infection.” You understand that “valuation multiples” is a financial term not a casual phrase. You grasp the intended meaning.
Machine translation teaches neural networks to do exactly the same thing: understand the meaning of text in one language and express that meaning accurately in another language. The crucial difference from simple word-for-word translation is that modern machine translation understands context, nuance, idiom, and meaning.
Evolution of Translation Technology
Three generations of machine translation technology have emerged:
| Approach | Era | How It Works | Quality Level |
|---|---|---|---|
| Rule-Based | Before 2015 | Hand-coded grammar rules. If English structure A-B-C, convert to French C-B-A | Poor. Brittle, failed on idioms and exceptions |
| Statistical | 2000-2017 | Learned patterns from billions of sentence pairs. Operated at word/phrase level | Fair. Better than rule-based, still struggled with context |
| Neural (Transformer-Based) | 2014-Present | Deep learning encodes meaning into vector representation. Understands entire document context | Excellent. Often exceeds human translator quality |
By 2026, transformer-based neural machine translation systems represent the frontier. These are the same transformer architectures powering large language models. A transformer can process an entire document simultaneously, understanding how each word relates to every other word, enabling translation that captures nuanced meaning across entire paragraphs and documents.
Why Machine Translation Became Critical in 2026
The business case for machine translation has never been stronger. Four major shifts created ideal conditions for enterprise adoption.
- First, enterprises became truly global. Remote work normalized across organizations. Every company competes globally. Social media connects customers across languages. Regulatory requirements expanded globally.
- Second, translation costs became a major operational expense. Global enterprises discovered that translation costs increase faster than revenue. Support teams grew, product launches multiplied, documentation requirements expanded.
- Third, customer expectations for multilingual support increased. Customers want support in their native language. Speed and cost matter. Machine translation made both possible.
- Fourth, the technology became production-ready. Transformer models and large language models now achieve human-competitive quality. APIs became affordable and accessible.
Real-World Impact: Proven Business Results
The Machine Translation Pipeline: How It Actually Works
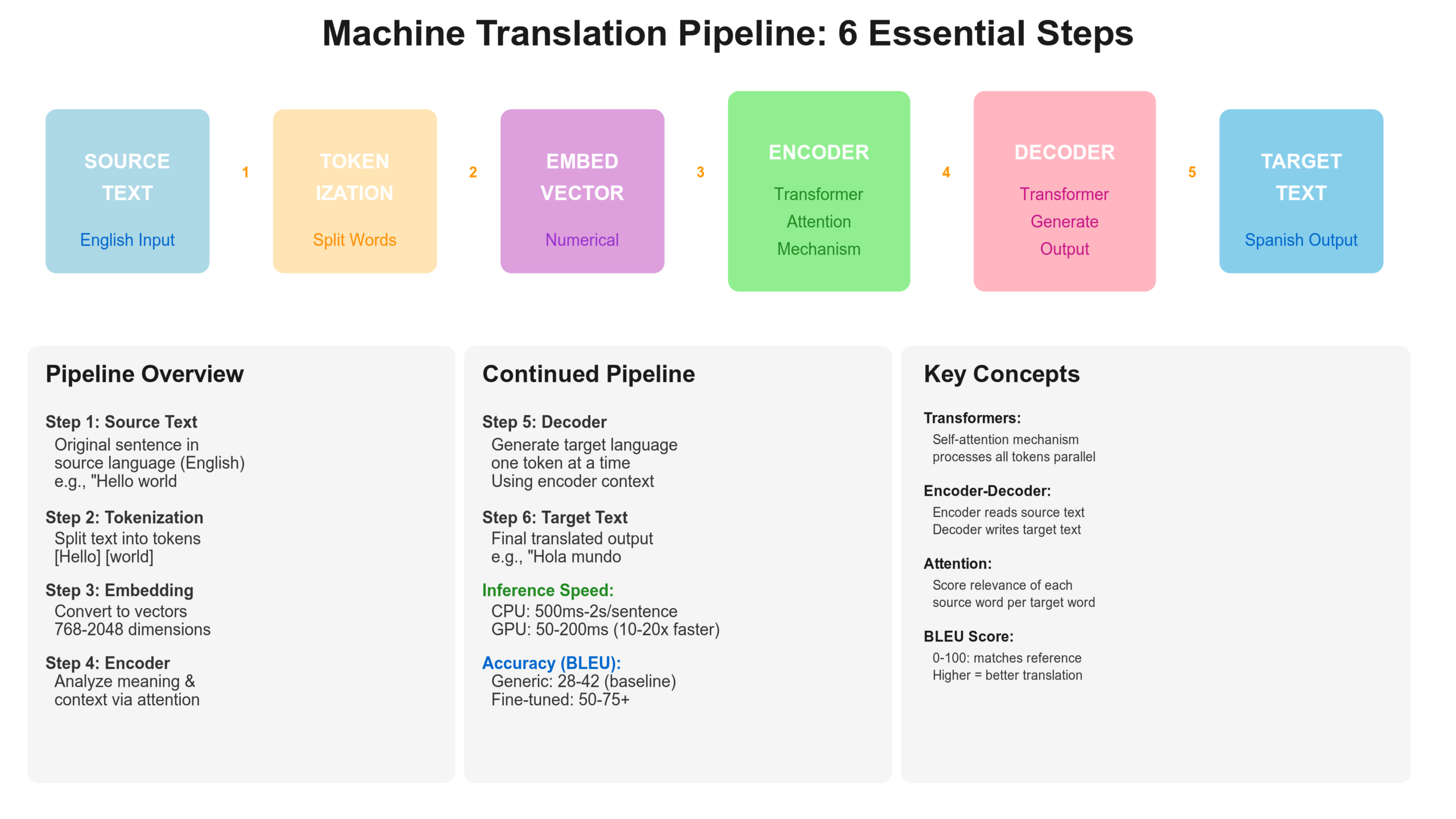
Understanding how machine translation systems transform source language text into target language text removes the mystery from the technology.
Step One: Text Preparation and Normalization
The system begins with raw text. It might contain special formatting, HTML tags, or encoding issues. Customer service chat messages might contain emojis and slang.
The system normalizes this text. Special characters are preserved where they matter. HTML tags are extracted or marked so they are not translated. Unicode encoding is standardized.
Step Two: Sentence Segmentation and Tokenization
Most machine translation systems work at the sentence level. The system breaks the text into sentences and tokenizes: breaking sentences into individual words or subword units called tokens.
In English, “do not” and “don’t” are treated as the same word. In languages like German with compound words, a single word might become multiple tokens.
Step Three: Embedding and Context Representation
Machine learning models work with numbers, not words. The system converts each token into a numerical vector, called an embedding, that captures semantic meaning.
The word “bank” in “river bank” gets a different embedding than “bank” in “savings bank” because context matters.
Step Four: Encoding the Source Language
The neural network encodes the source language sentence into a continuous representation that captures meaning. The encoder processes all tokens simultaneously and produces a high-dimensional vector representing the meaning of this entire sentence.
Transformer encoders with attention mechanisms are crucial here. Attention allows the model to recognize which words are describing nouns, which words are main actions, and the direction of relationships.
Step Five: Decoding Into the Target Language
The decoder takes the encoded meaning and generates the target language sentence one word at a time, using attention to focus on relevant parts of the source sentence.
This sequential generation allows the model to maintain grammatical coherence and generate fluent output.
Step Six: Post-Processing and Quality Refinement
Raw machine translation output sometimes requires refinement. Capitalization is fixed. Spacing is standardized. Named entities that should not have been translated are restored.
Modern systems also provide confidence scores. High confidence means the translation is reliable. Lower confidence means the source was ambiguous.
Deep Learning Approaches Powering Modern Machine Translation
Three primary deep learning approaches dominate enterprise machine translation in 2026.
Transformer-Based Neural Machine Translation
Transformer models represent the current best practice. Models like mBART, mT5, and mBART50 support translation between 50 to 100 language pairs with state-of-the-art quality.
Why transformers win:
- Scale to many language pairs efficiently
- Benefit enormously from pre-training on related languages
- Run fast on modern hardware
- Provide the highest translation quality
Real-World Example: A logistics company translates supply chain documents between 15 language pairs using a single fine-tuned model. This single model achieves better quality than maintaining 15 separate translation engines.
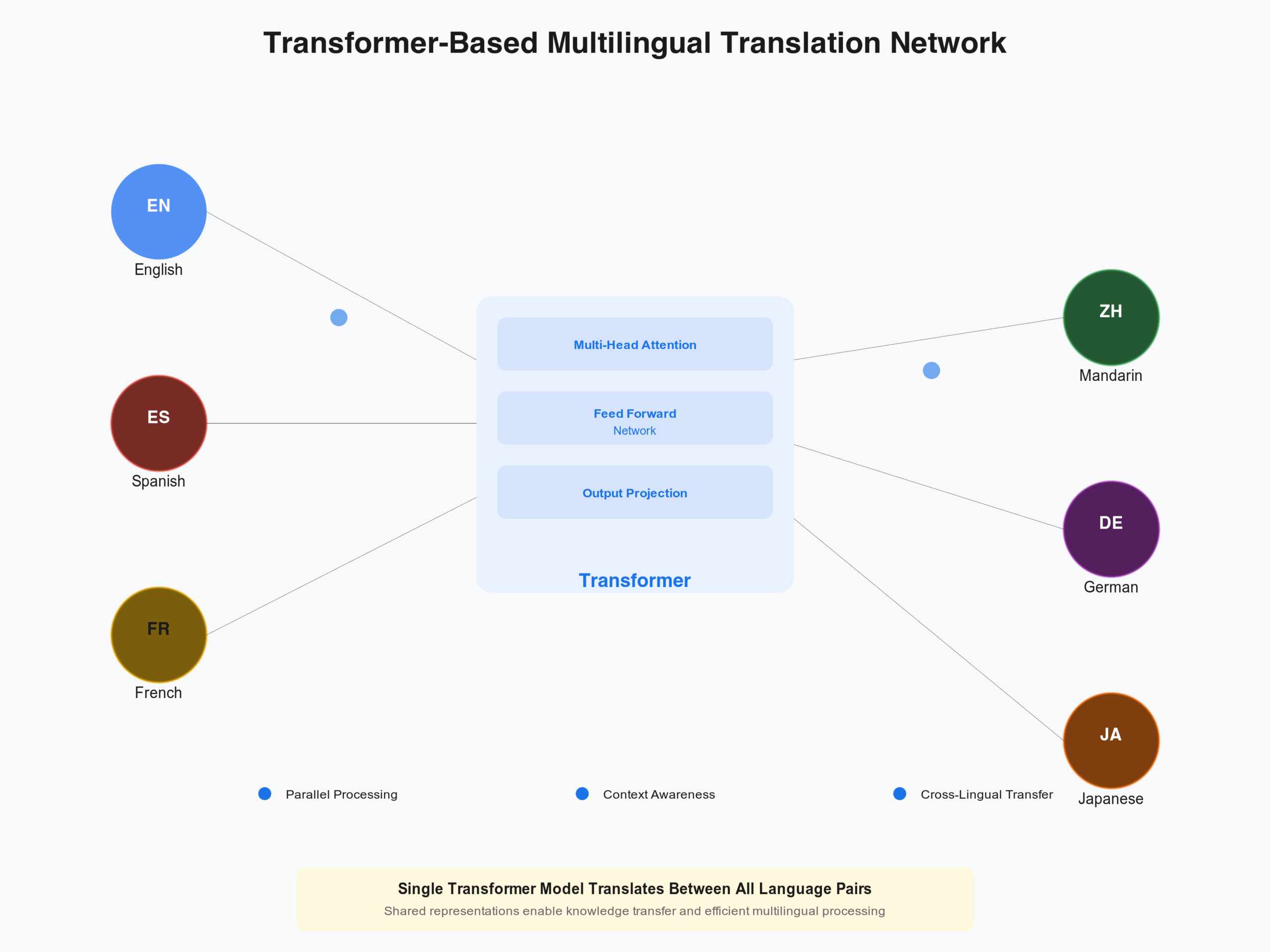
Understanding how transformers connect across multiple language pairs reveals their power. A single transformer model learns shared representations across all language pairs simultaneously. The network learns that concepts translate similarly across languages, enabling knowledge sharing.
Large Language Model Based Translation
GPT-4 and similar large language models brought a new paradigm. Instead of training a model specifically for translation, you prompt an LLM: “Translate the following English text to Spanish.” The model uses knowledge learned during general pre-training.
Advantages:
- Requires no language pair specific training
- Handles context and domain knowledge well
- Produces more fluent output than specialized models
- Can follow complex instructions like “preserve technical terms”
The main drawback is cost and latency. GPT-4 API costs significantly more than running a specialized translation model.
Hybrid Approaches
Many enterprises combine multiple approaches for optimal cost and quality:
- Real-time customer support: Fast but adequate machine translation
- Critical documents: Higher quality translation from language-specific models or LLMs
- High-volume batch translation: Cost-optimized smaller models
Getting Machine Translation Into Production: A Step-By-Step Guide
You understand the concepts. Now let me walk through implementing machine translation in your systems.
Step One: Define Your Language Pairs and Requirements
Start with your actual translation needs, not what you think you need. A company might say “we need 50 language pairs” but 80 percent of traffic is 5 language pairs: English, Spanish, French, Mandarin, German.
Prioritize by volume. A 5 percent improvement in Spanish-English translation that processes 50,000 documents monthly creates more business value than perfect translation of a language pair with 200 documents monthly.
Define quality requirements:
– Real-time chat translation: Tolerates lower quality
– Marketing materials: Requires higher quality
– Legal documents: Requires highest quality
Step Two: Data Preparation and Collection
The foundation of translation quality is data. Collect parallel corpora: authentic examples of documents in both source and target languages with human translations you trust.
Clean this data:
- Remove duplicates
- Verify source and target entries correspond
- Remove entries where translators provided wrong text
Step Three: Model Selection and Baseline
For most enterprises, start with an off-the-shelf pretrained model. Google Translate, Microsoft Translator, or open-source models from Hugging Face all provide starting points.
Measure baseline quality using BLEU score and human evaluation. This baseline tells you how much improvement fine-tuning provides.
Step Four: Fine-Tuning on Domain-Specific Data
If off-the-shelf models do not meet quality requirements, fine-tune a pre-trained model on your data.
Example: A healthcare system fine-tunes a translation model on 300 clinical documents. The fine-tuned model learns medical terminology. Quality improves from 28 BLEU to 36 BLEU.
Fine-tuning requires modest computational resources. A single GPU can fine-tune most models in 2-6 hours.
Step Five: Evaluation and Quality Assurance
Evaluate thoroughly before production:
- Use automatic metrics like BLEU score
- Supplement with human evaluation
- Have native speakers rate on adequacy, fluency, and domain appropriateness
- Set quality thresholds and confidence thresholds
Step Six: Integration and Deployment
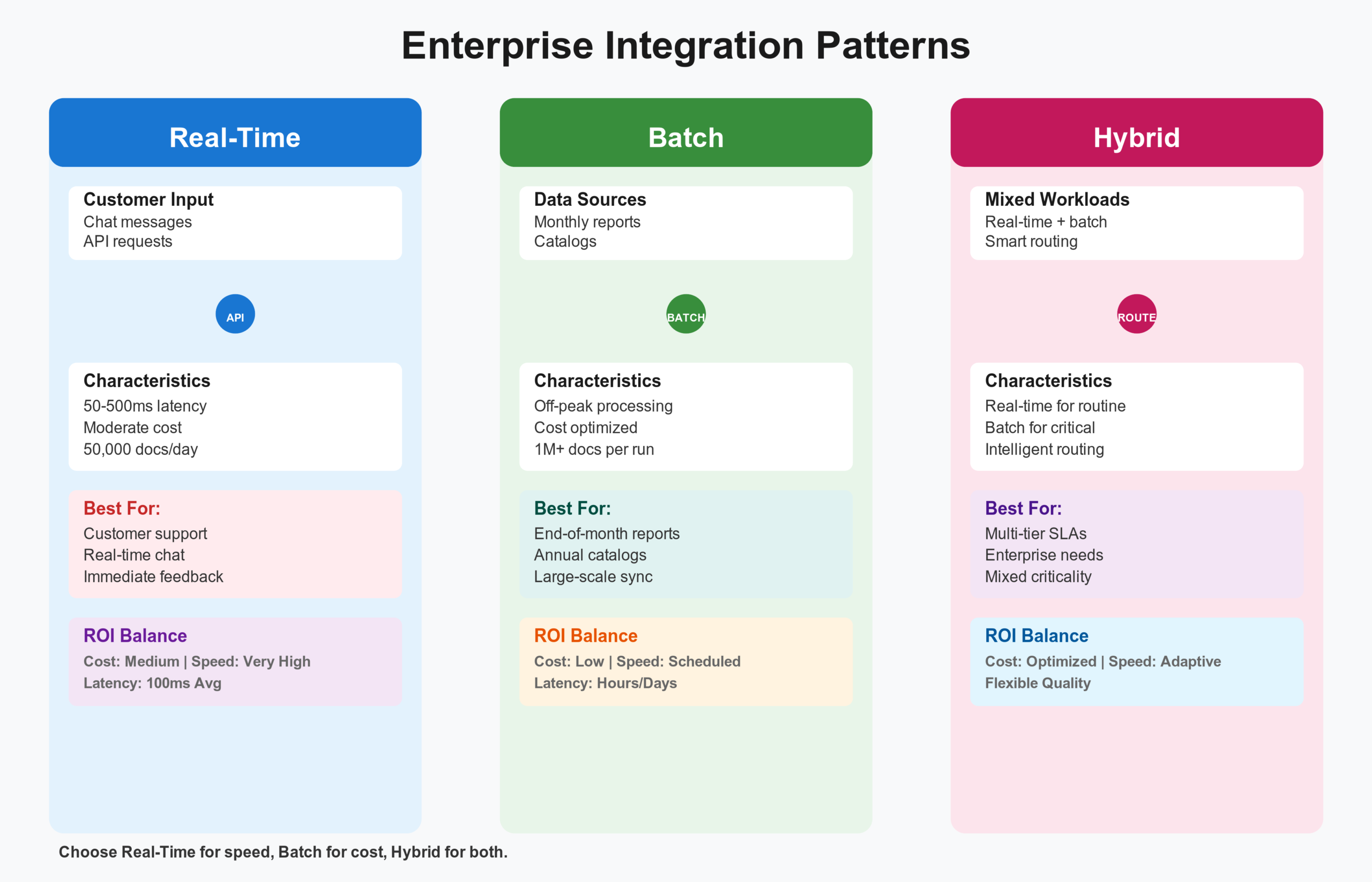
Deploy as an API service or batch processor:
- Real-time pattern: Containerized service, 50-500ms response
- Batch pattern: Process large volumes overnight, minimize compute costs
- Hybrid pattern: Real-time for routine content, batch with human review for critical content
Step Seven: Continuous Monitoring and Improvement
Monitor translation quality in production. A percentage of translations should be reviewed by humans monthly. This feedback improves the system through retraining.
Set up feedback mechanisms. Users can rate translation quality. Particularly poor translations are logged for manual review.
Measuring Machine Translation Quality
Understanding machine translation quality requires looking beyond simple word counts.
BLEU Score
BLEU (Bilingual Evaluation Understudy) compares machine-generated translations to professional human translations by counting how many words and phrases match.
BLEU Score Interpretation:
- 40-50 BLEU: Human-competitive translation for general English-German
- 50-60 BLEU: Good translation quality
- 60-70 BLEU: Very good translation quality
- Above 70 BLEU: Only achievable on narrow domains with excellent data
Most practical enterprise systems achieve 35-55 BLEU on general translation and 50-70 BLEU on specialized domains.
Human Evaluation Metrics
Have native speakers evaluate on a 1-5 scale:
1. Inadequate
2. Poor
3. Fair
4. Good
5. Excellent
Most production systems maintain 3.8-4.2 average human rating.
Real-World Quality Expectations
English to Western European Languages (Spanish, French, German):
- Generic models: 40-50 BLEU
- With domain fine-tuning: 50-65 BLEU
- With extensive fine-tuning: 65-80 BLEU
Technical Documentation, Legal, Specialized:
- With fine-tuning: 50-65 BLEU
- With extensive curation: 70-85 BLEU
Rare Languages or Limited Training Data:
- Expected: 20-35 BLEU
- Human post-editing becomes necessary
If your results are significantly lower, you likely have: inadequate training data, poor data quality, domain mismatch, or vocabulary mismatch.
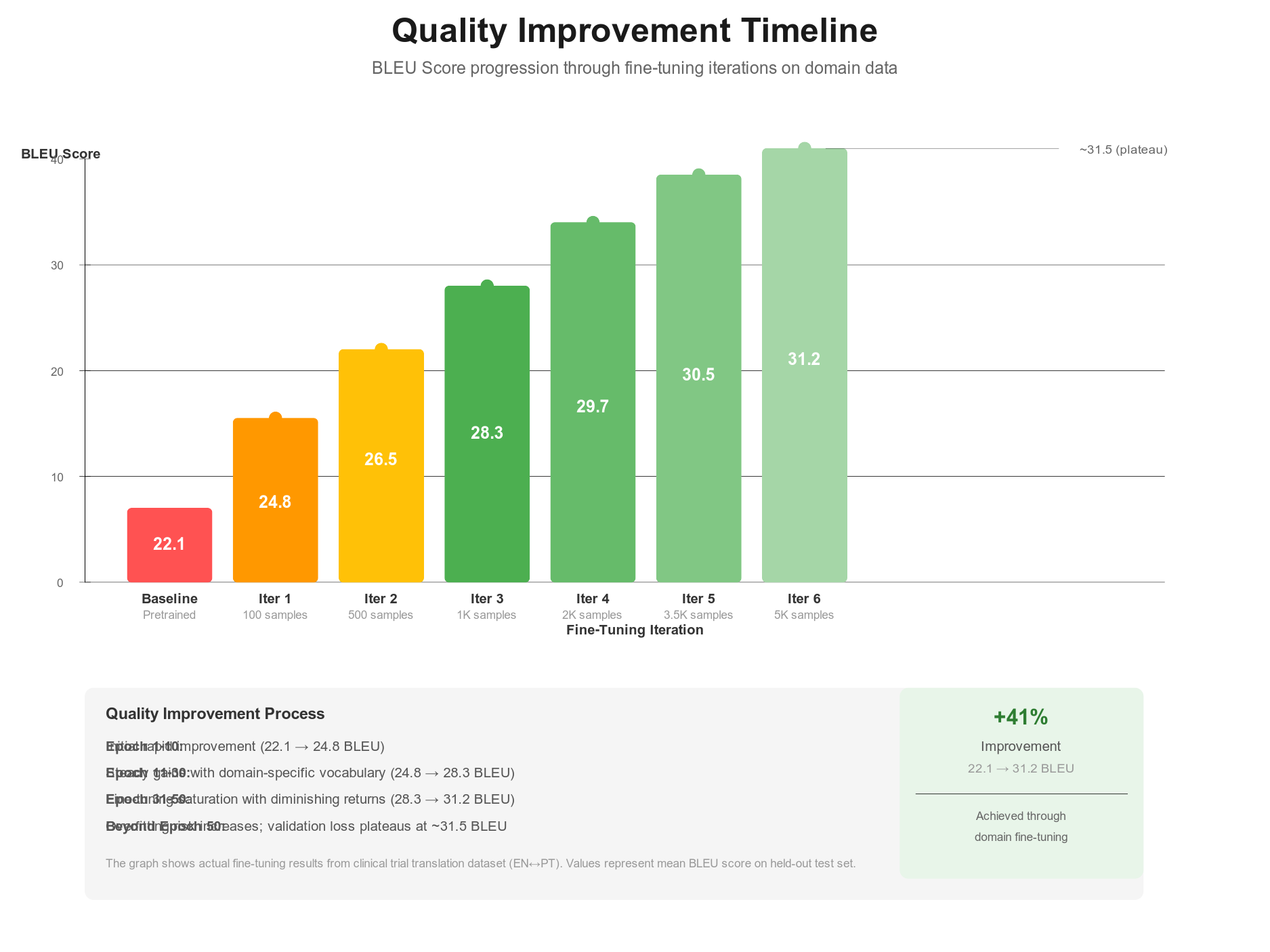
Real-World Use Case: Healthcare Translation
A hospital system needed to serve non-English speaking patients across 18 languages. Previously, they hired interpreter services at $150-200 per hour, creating access barriers.
They implemented machine translation with human review. Patient intake forms translate automatically to English. Provider responses translate back to patient language. Critical information gets human review.
The system is not perfect. Some medical terminology translates poorly. Machine translation improved from 22 BLEU initially to 31 BLEU after fine-tuning on 400 medical documents.
Business Outcome: 76 percent of patient interactions are now fully automated. Critical interactions get human review. Patient wait times reduced 40 percent. Hospital expanded care to 12 additional language communities.
Challenges You Will Encounter and Solutions That Work
Implementing machine translation at scale reveals practical challenges.
Challenge One: Gender and Formal Language Rules
Languages like Spanish, French, and German have grammatical gender. Formal and informal speech matter.
Solution: Provide context about target audience and formality level. Domain-specific fine-tuning helps the system learn appropriate register.
Challenge Two: Culturally Specific References
“Americans love apple pie” translates literally but sounds wrong to people unfamiliar with the culture. Names and places need different handling.
Solution: Create glossaries of domain-specific terminology. Use named entity detection to identify proper nouns that should not be translated.
Challenge Three: Idioms and Colloquialisms
“It is raining cats and dogs” means heavy rain in English but translates nonsensically to most languages.
Solution: Prepare a glossary of idioms. For critical documents, human review catches these. Fine-tuning on idiomatic expressions helps.
Challenge Four: Low-Resource Languages
Languages like Somali, Quechua, or Uyghur have limited training data. Building direct translation systems fails.
Solution: Pivot translation through a high-resource language. Back-translate to detect errors: generate English from Somali, then translate back to Somali.
Challenge Five: Domain-Specific Terminology Evolution
Software developers introduce new terminology constantly. Your system must adapt.
Solution: Maintain a living glossary of domain terms. Implement continuous feedback and retraining. Set aside 2 percent of domain experts’ time for validation.
Integrating Machine Translation Into Your Business Systems
Understanding the technology matters only if you can integrate it effectively.
Real-Time Translation Pattern
You have high-volume incoming text requiring immediate translation: customer support chat, product descriptions, user-generated content filtering.
Architecture: Containerized translation service with an API. Clients send source text, receive translation in 50-500 milliseconds.
Cost: Process approximately 50,000 documents daily on moderate hardware for approximately $2-3 daily. Cost per million documents: $40-60.
Batch Translation Pattern
You have large volumes of periodic content: monthly financial reports, annual product catalogs, archive processing, content platform localization.
Architecture: Submit batch jobs processing large volumes overnight. Store results in a database. Minimize compute costs through batching.
Cost: Using spot instances and efficient batching, processing 1 million documents costs approximately $15-25.
Hybrid Pattern with Quality Assurance
High-value transactions get better treatment. Critical documents require human review. Routine documents use machine translation without review.
This hybrid approach maximizes efficiency while ensuring critical content quality.
The Future of Machine Translation: What Is Coming
Machine translation continues to advance rapidly.
Real-Time Multilingual Conversation
Systems that translate speech simultaneously in multilingual conversations. A meeting with participants in English, Spanish, French, and Mandarin proceeds smoothly with each participant understanding in their native language.
Document-Level Coherence
Current systems translate sentence by sentence. Future systems maintain consistency across entire documents. All occurrences of a term use the same translation. Pronouns and references are maintained correctly across paragraphs.
Specialized Domain Models
Healthcare translation models understand medical terminology better than general models. Legal translation models preserve precise meaning. Financial services translation models maintain accuracy on complex commercial language.
Multimodal Translation
Text translation is standard. Image and video translation is emerging. Systems translate text in images while preserving layout. Videos are automatically dubbed or subtitled.
Post-Editing Automation
Systems identify uncertain parts of machine translation and request human post-editing of only those segments. This is 3-5 times faster than full human translation.
Key Takeaways
Machine translation is production-ready technology. It is no longer experimental research. Thousands of production systems across every industry deploy machine translation daily.
The business case is compelling. Enterprises report 85 percent reduction in translation costs, 92 percent improvement in time-to-market, and 96 percent improvement in customer support responsiveness.
The technology is accessible. Open-source models through Hugging Face are free. Cloud providers offer inexpensive translation APIs. You can implement production machine translation without significant capital investment.
The challenge is integration, not technology. Choosing which language pairs matter most, determining acceptable quality, integrating into your workflow, and managing feedback loops is the real challenge.
Start small and iterate. Test pre-trained models first. Move to fine-tuning only if necessary. Integrate progressively into high-impact systems. Measure improvement at each step.
Technical Resources
1. Hugging Face Transformers for Translation: huggingface.co/docs/transformers/tasks/translation
2. Google Cloud Translation API: cloud.google.com/translate/docs/basic/setup
3. OpenNMT for Custom Models: opennmt.net
4. WMT Evaluation Workshop: wmt-metrics.github.io
5. Machine Translation Datasets: statmt.org
Related Articles
If you found this article valuable, explore my previous article on Named Entity Recognition, which discusses how to automatically extract and classify entities from text. In enterprise NLP pipelines, NER comes before machine translation. You identify what entities are present, then translate that information for global understanding.