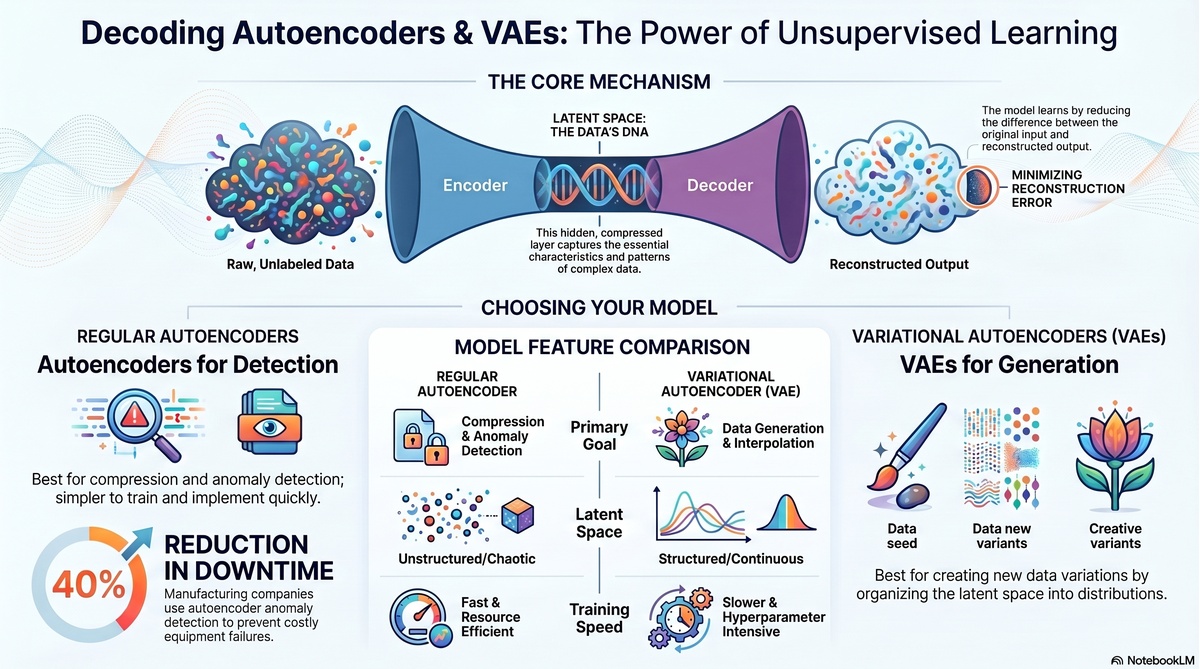
Master autoencoders and VAEs—the revolutionary unsupervised learning techniques transforming AI. Learn how companies use these to generate content, compress data, and solve complex problems without labeled datasets.
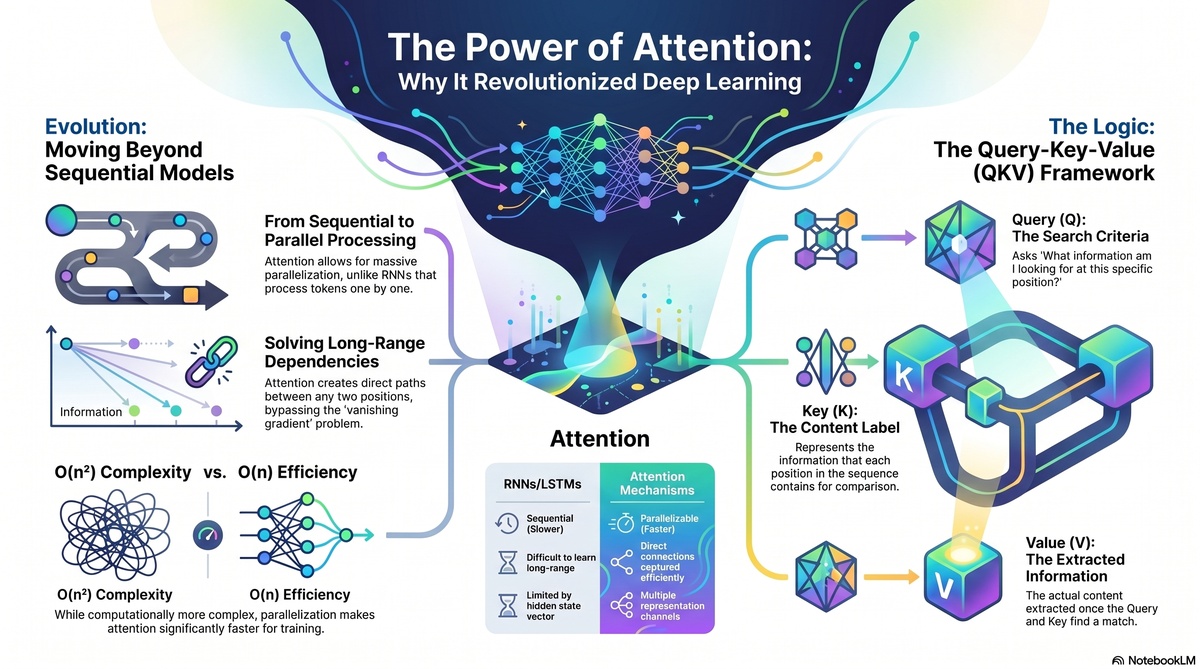
Discover how attention mechanisms power modern AI systems. Learn how transformers revolutionized NLP and why every AI architect needs to understand selective focus.
Master transfer learning for NLP with production strategies using BERT, GPT, and T5. Learn how top AI teams deploy language models at scale with 70% cost reduction in 2026.
Master transfer learning for computer vision with practical strategies and enterprise deployment patterns. Learn proven techniques to accelerate vision model development and reduce costs by 80% in 2026.
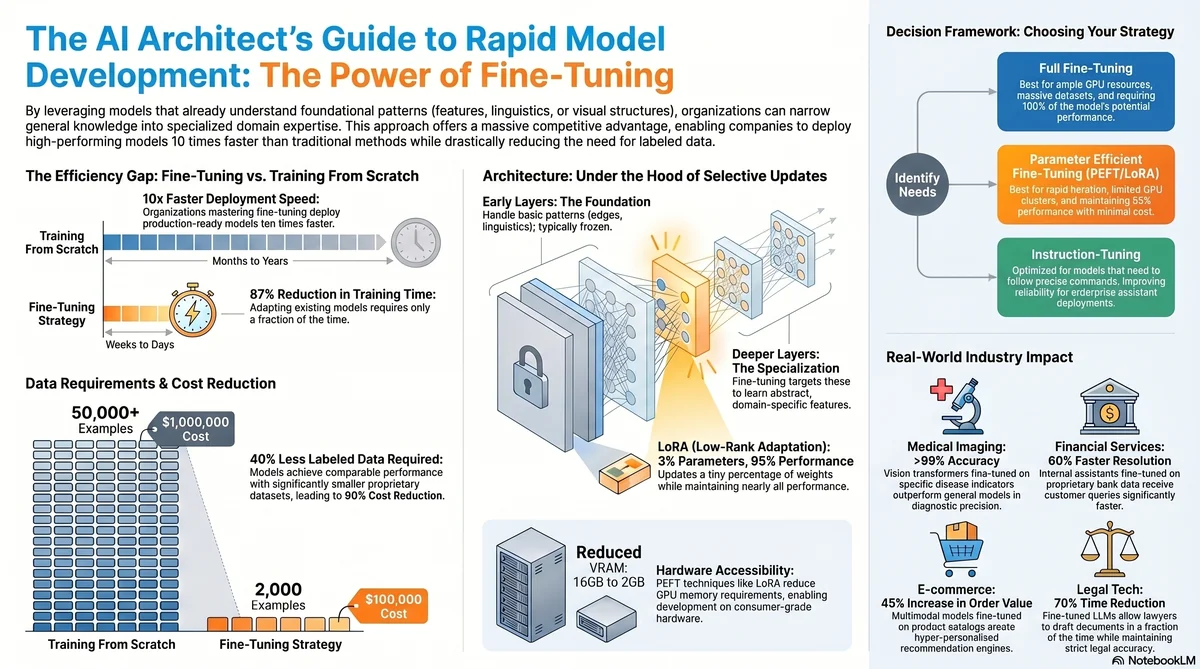
Master fine-tuning of pretrained models to accelerate AI development. Learn proven strategies, real-world applications, and best practices from industry leaders in 2026.
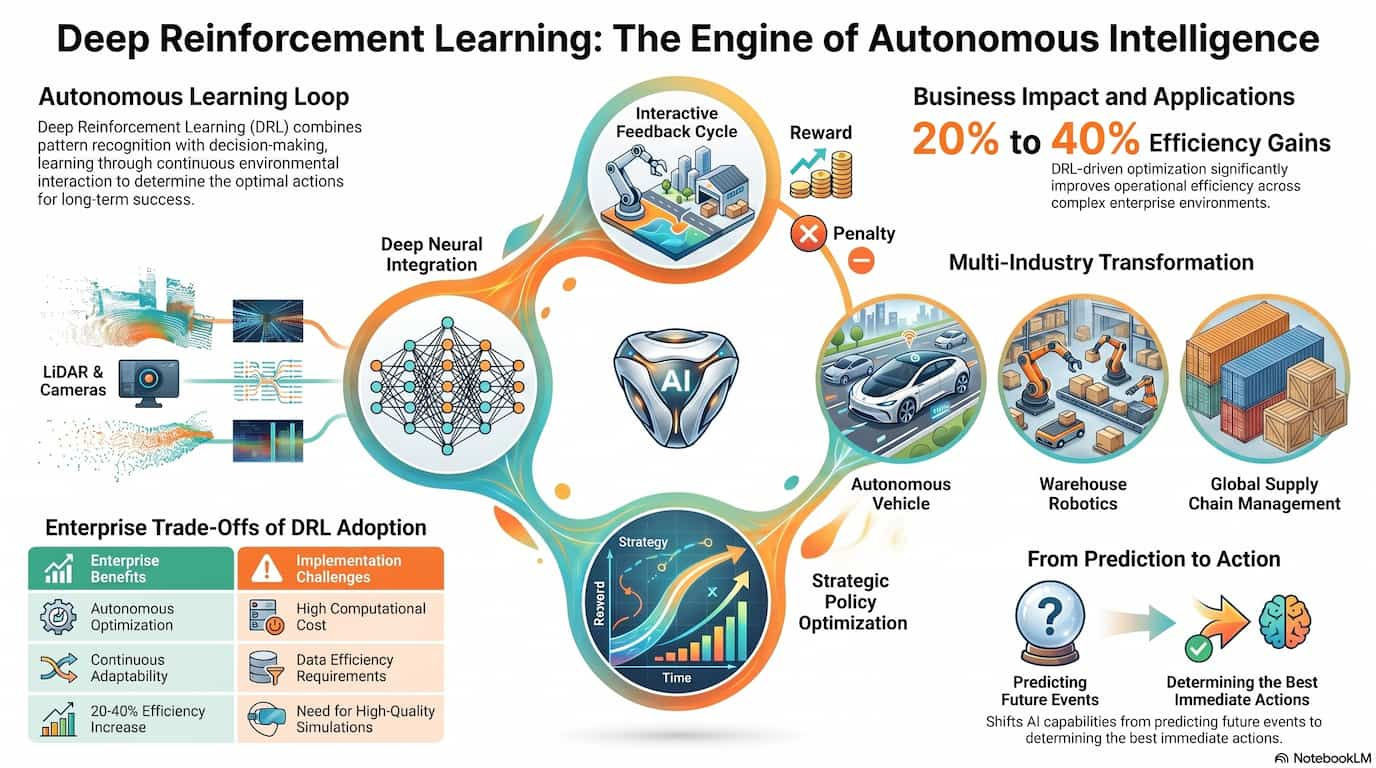
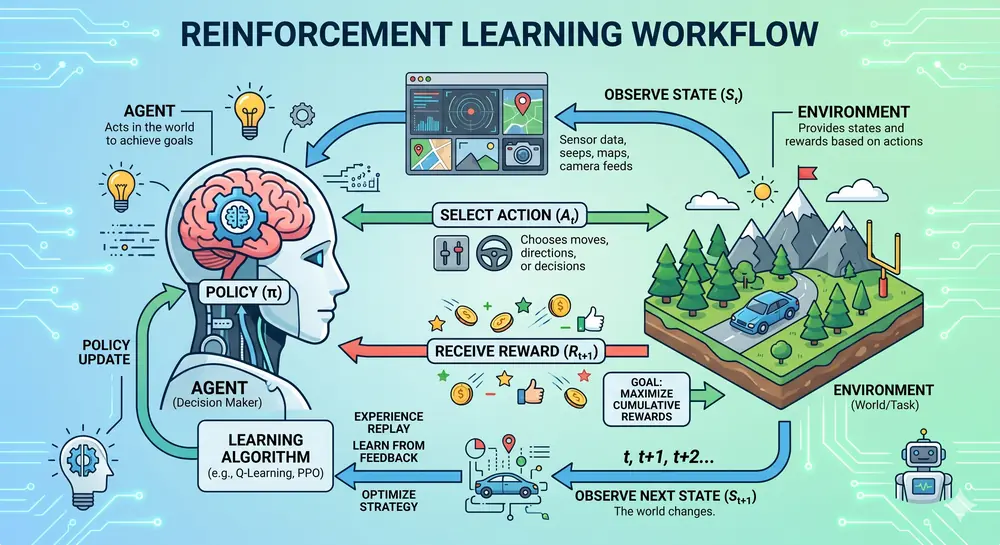
Learn how reinforcement learning and sequential deep learning drive autonomous systems, recommendations, and business intelligence. Real-world applications for enterprises.
Learn how deep learning models like LSTMs and Transformers generate music from sequential data, with practical use cases across media, gaming, and content.