The intersection of artificial intelligence and creative industries represents one of the most transformative developments in technology today. Deep learning has fundamentally changed how we approach complex problems involving sequences, patterns, and temporal relationships. When it comes to music generation, this technology has moved far beyond simple algorithmic composition into a realm where machines can create sophisticated, emotionally resonant pieces that rival human composers.
For technology executives and business leaders, understanding deep learning for sequential data and its application to music generation is crucial. This knowledge directly translates to competitive advantage in multiple sectors including entertainment, advertising, gaming, and content creation. The music generation market alone is projected to reach significant value as AI tools become mainstream creative partners in studios and creative agencies worldwide.
Understanding Sequential Data in the Context of Music
Music is fundamentally sequential data. Each note follows another, each chord progression builds on previous harmony, and the entire composition unfolds over time with specific relationships and dependencies. This temporal nature makes music the perfect use case for deep learning architectures designed to process sequences.
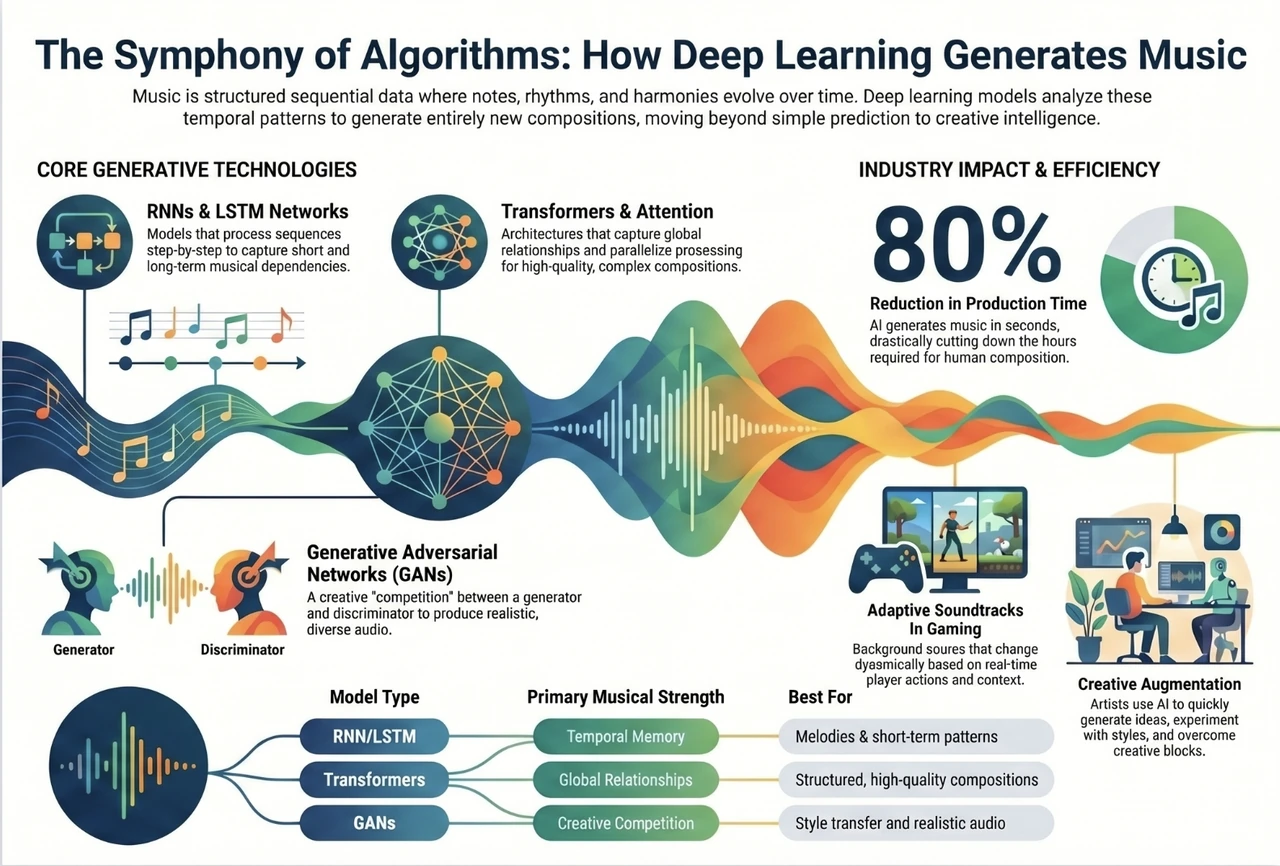
Sequential data differs from typical independent data points. In music, the context matters profoundly. A C major chord resolution means something different depending on what came before it. A drum beat pattern creates anticipation based on established rhythm. This contextual relationship is where deep learning excels compared to traditional machine learning approaches.
The key challenge with sequential data is capturing long-term dependencies. In a musical composition lasting several minutes, decisions made by the algorithm must remain consistent with patterns established much earlier. This is where advanced neural network architectures become essential.
The Foundations: Recurrent Neural Networks and Beyond
Recurrent Neural Networks (RNNs) were among the first deep learning architectures specifically designed to handle sequential data. Unlike feedforward networks that process each input independently, RNNs maintain a hidden state that evolves as they process sequences. This hidden state acts as a memory, allowing the network to leverage information from previous time steps.
However, traditional RNNs suffered from significant limitations. As sequences became longer, gradients would either vanish or explode during backpropagation, making it difficult for networks to learn long-term dependencies. For music generation, this meant the algorithm would struggle to maintain coherence in longer pieces.
Long Short-Term Memory (LSTM) networks revolutionized sequential processing by introducing memory cells and gating mechanisms. These gates control what information flows through the network, allowing important patterns to persist while less relevant information fades. For music generation, this means an LSTM can maintain the key modulation established at the beginning of a composition while processing hundreds of bars of music.
Gated Recurrent Units (GRUs) provided a simplified alternative to LSTMs with similar performance characteristics but fewer parameters, making them computationally more efficient. In production music generation systems, this efficiency often makes GRUs the practical choice.
Transformer Architecture: A Paradigm Shift in Music Generation
While RNNs, LSTMs, and GRUs dominated for years, the introduction of the Transformer architecture in 2017 fundamentally changed how we approach sequential data processing. Rather than processing sequences step by step, Transformers use self-attention mechanisms to weigh the importance of all positions in a sequence simultaneously.
For music generation, Transformers offer several critical advantages. First, they process entire sequences in parallel rather than sequentially, enabling faster training and inference. Second, the attention mechanisms can capture both local relationships between adjacent notes and global relationships across entire compositions. Third, they scale more effectively to longer sequences than previous architectures.
Models like OpenAI’s MuseNet and Google’s Music Transformer have demonstrated that Transformer-based systems can generate coherent, musically interesting compositions lasting several minutes. These systems can maintain consistent stylistic elements, respect musical form, and even coordinate multiple instruments realistically.
The Mechanics of Neural Music Generation
The fundamental approach to neural music generation involves three key phases: tokenization, modeling, and decoding.
In tokenization, musical elements are converted to a numerical representation that neural networks can process. This might involve representing each note, velocity, duration, and timing as individual tokens. Some approaches use MIDI data directly, while others work with audio spectrograms or other musical representations.
The modeling phase involves training a neural network on vast datasets of musical examples. The network learns statistical patterns about how music typically unfolds. As the architecture processes sequences during training, it learns that certain chord progressions are more likely than others, that specific rhythmic patterns tend to follow others, and that instruments interact in particular ways.
During generation, the decoder uses the learned patterns to sample the next token probabilistically. Rather than deterministically choosing the most likely next note, the system samples from a probability distribution. This stochasticity is crucial for generating diverse, creative outputs rather than always producing identical repetitive music.
Addressing the Challenges of Music Generation
Generating coherent, musically satisfying compositions presents unique technical challenges that differ from other sequential data applications like language modeling.
Temporal Coherence remains difficult. A language model generates readable sentences if words statistically follow each other. Music generation requires maintaining harmonic consistency, rhythmic stability, and tonal relationships across time scales ranging from milliseconds to minutes. A single wrong note can undermine an entire passage, whereas a single misspelled word has limited impact on document readability.
Style Consistency presents another challenge. Human composers naturally maintain their stylistic choices throughout a piece. Generating music where every section sounds coherent with the overall aesthetic requires the model to learn and apply implicit stylistic constraints. This is why fine-tuning models on specific composers or genres significantly improves generation quality.
Controllability in generation is crucial for practical applications. Users want to specify musical parameters like genre, tempo, key, instrumentation, and mood without training entirely new models. Recent approaches use prompt conditioning and control tokens to guide generation toward desired characteristics.
Real-World Applications Driving Innovation
The music generation space is no longer purely experimental. Multiple practical applications are moving from research to production deployment.
Content Creation for Media and Entertainment has become mainstream. Streaming platforms, game developers, and advertising agencies increasingly use AI-generated music for background scores, ambient music, and placeholder compositions. Companies like Amper Music and Jukebox have commercialized music generation systems that creative professionals now integrate into their workflows.
Music Production and Assistance represents another significant application area. Rather than replacing composers, these tools assist professional musicians. They generate initial melodic ideas, suggest chord progressions, or create arrangement variations. This collaborative approach between human creativity and machine intelligence is becoming the standard in modern music production.
Therapeutic Applications have emerged in healthcare settings. Researchers have demonstrated that AI-generated personalized music can aid in pain management, stress reduction, and cognitive rehabilitation. The ability to rapidly generate music tailored to individual preferences and therapeutic goals opens new possibilities in wellness applications.
Custom Music for Interactive Experiences matters increasingly as gaming and virtual reality expand. Rather than static audio tracks, these experiences require music that adapts to player actions in real time. Deep learning models capable of generating musically coherent sequences on demand enable responsive soundscapes that enhance immersion.
The Data Revolution Behind the Models
The quality of generated music depends fundamentally on training data. Models trained on diverse, high-quality musical datasets significantly outperform those trained on limited data. Organizations building production music generation systems invest extensively in curating comprehensive training datasets.
The MAESTRO dataset contains thousands of hours of pianist performances. MusicNet provides thousands of full recordings with detailed annotations. These open-source datasets have accelerated research, enabling researchers worldwide to develop and benchmark new approaches without starting from scratch.
The importance of quality data extends across all AI applications. Music generation exemplifies this principle. The models themselves, regardless of architectural sophistication, cannot generate meaningful patterns that did not exist in training data. This reinforces why organizations investing in robust music generation capabilities prioritize data quality and diversity.
Technical Considerations for Implementation
Organizations considering music generation implementation face several critical decisions. First, should they build custom models or leverage existing platforms and APIs? Building custom models provides complete control but requires significant ML expertise and computational resources. Platforms like OpenAI’s API or specialized music generation services provide faster time-to-market with less infrastructure burden.
Second, what musical representation and tokenization approach best serves specific use cases? Different applications favor different representations. Games might prioritize real-time generation and responsiveness, favoring symbolic representations. Film scoring applications might favor predictions of audio spectrograms. Different tokenization choices profoundly affect downstream model performance.
Third, how should models be fine-tuned or adapted for specific styles, genres, or use cases? Transfer learning allows models trained on broad musical data to be efficiently adapted. Starting with a well-trained foundation model and fine-tuning on domain-specific data often outperforms training from scratch with limited data.
Evaluating and Comparing Generated Music
Unlike language generation, which humans easily evaluate for coherence and grammar, evaluating music generation quality remains partly subjective. Automated metrics have emerged to provide quantitative evaluation, but they cannot fully capture musical satisfaction.
Some metrics measure consonance and tonal harmony, assessing how well generated music adheres to traditional harmonic principles. Others measure rhythmic regularity and predictability. Machine learning researchers have developed novel evaluation approaches using embeddings trained to predict human musical preferences.
However, human evaluation remains essential for production systems. A/B testing where listeners compare generated music against baseline approaches and human compositions provides the most reliable assessment of quality. This human-in-the-loop evaluation guides model improvements and validates that technical metrics correlate with real musical quality.
The Future: Emerging Trends and Directions
Several trends are shaping the immediate future of music generation technology. Multimodal approaches combining audio, text, and other data modalities are enabling more intuitive interfaces to music generation. Users might describe desired music in natural language, and systems generate audio matching the description. This democratizes music creation for non-musicians.
Cross-modal generation, where systems generate music from images or vice versa, represents another frontier. The ability to translate between artistic domains suggests deeper understanding of creative principles underlying music and visual art.
Personalized and adaptive music generation tailored to individual listeners is becoming increasingly sophisticated. Rather than generating identical music for all users, systems learn individual preferences and generate music specifically refined to match each person’s taste and listening history. This has profound implications for music recommendation and the future of personalized content.
Real-time interactive music generation, where systems adjust music in response to environmental factors or user interaction, promises new forms of musical experience. Imagine live performances where AI assistants generate accompaniment, variations, or new material responding to lead performers in real time. This collaborative future between human and machine musicians is rapidly approaching.
Addressing Ethical and Rights Considerations
As music generation technology becomes mainstream, ethical and legal questions become increasingly important. Training models on existing music raises copyright questions that the music industry and policymakers are currently debating. Finding fair approaches that reward human creators while enabling AI innovation remains an active challenge.
Transparency and disclosure matter significantly. When AI-generated music is used in commercial contexts, disclosure to consumers ensures informed consumption. Understanding whether music one encounters was generated by humans or machines informs consumer choice and maintains trust.
Bias in training data can lead to biased outputs. If training data emphasizes music from particular cultures or genres, generated music may reflect those biases rather than true musical diversity. Building inclusive, representative training datasets represents an ongoing priority for the community.
Implementation Roadmap for Organizations
Organizations considering music generation capabilities should follow a structured approach. Initial assessment phase involves evaluating specific use cases and determining whether off-the-shelf solutions meet needs or custom development becomes necessary. Pilot projects with limited scope and controlled budgets allow organizations to assess feasibility and value.
Development and integration phase involves selecting appropriate architectures, assembling training data, and building integration layers with existing systems. This phase requires ML expertise and significant computational resources. Partnering with specialized firms or leveraging cloud-based ML services often accelerates this phase.
Evaluation and iteration involves rigorous testing of output quality, collecting human feedback, and continuously improving models. This is an ongoing process where feedback loops between human evaluators and model developers drive continuous improvement.
Conclusion: Music Generation as a Strategic Technology
Deep learning for sequential data, exemplified through music generation, represents far more than an interesting academic research area. It is an emerging strategic technology reshaping how creative industries operate. Organizations that develop capabilities in music generation, whether through internal teams or external partnerships, gain competitive advantages in gaming, entertainment, advertising, and content creation.
The technical foundations are solid. Transformer architectures, attention mechanisms, and advanced training techniques enable systems to generate musically coherent, high-quality compositions. Real-world applications demonstrate genuine value and market demand. The convergence of computational power, algorithmic advances, and available training data means the technology is approaching practical maturity.
For technology leaders and strategists, now is the appropriate time to build understanding and explore applications within your organization. Music generation exemplifies broader principles of applied deep learning that transfer to other domains. By engaging with this technology, your organization gains insights applicable far beyond music to any challenge involving sequential data, temporal relationships, and creative generation.
The fusion of artificial intelligence and musical creativity represents humanity advancing toward a future where machines augment and amplify human creative potential. Understanding and leveraging this technology positions organizations at the forefront of this transformation.
Related Reading
For additional AI insights, explore our earlier deep learning article and browse more posts on the main blog.