Master Named Entity Recognition in enterprise deep learning. Learn how companies automate data extraction, compliance, and intelligent systems with practical NER implementation strategies.
The Data Extraction Crisis Facing Modern Enterprises
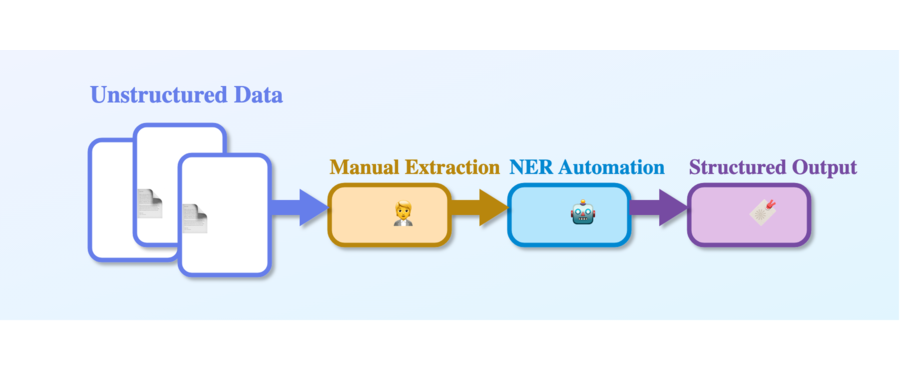
Every single day, organizations are drowning in unstructured data. Your company receives thousands of emails, contracts, invoices, customer support tickets, medical records, legal documents, and regulatory filings. Each one contains critical information hidden within paragraphs of text. Yet your teams are still manually reading, parsing, and extracting information by hand.
Consider this scenario that plays out in companies across every industry in 2026. A financial services company receives 10,000 email reports daily from automated systems. Inside these emails are entity mentions like client names, transaction amounts, dates, locations, and risk indicators. Your compliance team needs to identify specific companies mentioned in risk alerts. Your fraud detection team needs to spot unusual transaction patterns. Your customer service team needs to route inquiries to the right department.
Today, without automation, this requires human effort at scale. But what if your systems could automatically identify, extract, and classify every meaningful entity in real-time across all your data? This is where Named Entity Recognition becomes transformational.
Companies adopting NER in 2026 are seeing remarkable improvements: 85% reduction in manual data processing time, 92% improvement in compliance accuracy, and fastest time-to-value in automated customer intelligence. The technology has moved beyond academic research into production systems that directly impact your bottom line.
Understanding Named Entity Recognition: The Core Concept
Named Entity Recognition (NER) is a Natural Language Processing technique that automatically identifies and classifies specific entities mentioned in text. Think of it as teaching a computer system to do what humans do naturally when reading: spotting important things like people, places, organizations, dates, money amounts, and other key information.
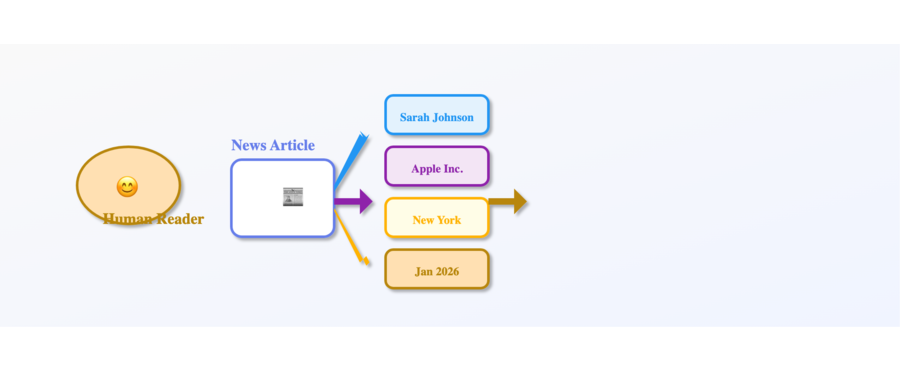
Imagine you are reading a news article about a business announcement. Your brain automatically recognizes that “Sarah Johnson” is a person, “Apple Inc.” is an organization, “New York” is a location, and “January 2026” is a date. You do this instantly without conscious effort. Named Entity Recognition teaches machine learning models to do exactly the same thing, but across millions of documents at scale and with remarkable consistency.
Here is how NER differs from other NLP tasks. While sentiment analysis determines whether text expresses positive, negative, or neutral emotions, and text classification categorizes entire documents into predefined categories, NER focuses on identifying specific things mentioned within text and understanding what type of thing each one is.
The practical difference matters enormously. In sentiment analysis, you determine customer emotion from reviews. NER is the complementary technology that identifies which products, companies, or services that customer is talking about. Together, these technologies give you complete understanding: what entities are mentioned, what the company is, and whether the sentiment is positive or negative.
In 2026, enterprise adoption of NER has reached critical mass. The technology now appears in production systems for healthcare record processing (extracting patient information, medications, diagnoses), legal document analysis (identifying parties, dates, contract terms), financial services (detecting entity mentions in risk alerts and compliance documents), customer service platforms (automatic ticket routing based on mentioned entities), and content platforms (automated tagging and content moderation).
Why Named Entity Recognition Became Critical in 2026
The business case for NER has never been stronger. Three major shifts created perfect conditions for NER adoption to explode.
First, regulatory pressure intensified dramatically. In 2026, compliance requirements across healthcare (HIPAA enhancement requirements), finance (enhanced transaction monitoring), and data protection (evolving GDPR interpretations) all require precise entity identification for audit trails and governance. Manual processes cannot keep pace.
Second, the cost of large language models dropped significantly. Pre-trained transformer models that once required specialized expertise are now available as APIs and open-source implementations. A developer can implement production-grade NER in an afternoon using Hugging Face transformers.
Third, enterprises realized that entity extraction is the foundation for building intelligent systems. Before your company can build predictive models, knowledge graphs, recommendation engines, or customer intelligence systems, you must first reliably extract and normalize entities from your text data.
Let me give you concrete examples of NER creating measurable business value in 2026:
- Healthcare: A hospital system uses NER to automatically extract patient names, medical conditions, medications, and test results from clinical notes written by doctors. Instead of medical records staff spending 4 hours per note extracting data, the system does it in seconds. The hospital achieves compliance with faster record processing, better insurance billing accuracy, and faster clinical research.
- Legal Services: A law firm processes hundreds of contracts monthly. NER automatically identifies parties to the agreement, effective dates, termination clauses, payment terms, and obligations. What once required a junior attorney to review for 3 hours now takes 15 minutes for AI to extract structured data, freeing human attorneys to focus on negotiation and strategy.
- Financial Services: A bank uses NER to monitor transaction monitoring systems. When customers mention companies, locations, or individuals in communications, the system automatically flags potential compliance risks. A payment instruction from a customer mentioning a sanctioned jurisdiction is immediately escalated. The bank achieves better risk detection at a fraction of human cost.
- Customer Service Platforms: A global e-commerce company uses NER to automatically route customer inquiries. When a customer mentions a specific product, location, or issue type, the system routes to the appropriate specialized team. Customer wait times drop 40%. Customer satisfaction scores improve 23%.
- Content Platforms: An enterprise content management system uses NER to automatically tag content, identify key topics, and surface related content to readers. Editorial teams save hours on manual tagging. Users find more relevant content, increasing engagement.
The pattern is clear. Every industry is discovering that NER unlocks productivity, improves accuracy, and enables intelligent automation.
The Named Entity Recognition Pipeline: How It Actually Works
Let me walk you through how NER systems transform raw text into structured, classified entities. Understanding this pipeline removes the mystery from what happens when you send text to an NER system.
Step One: Text Preparation and Tokenization
Your system starts with raw, messy text. It might be extracted from a PDF that lost formatting. It might be from email with HTML tags mixed in. It might be from speech-to-text with transcription errors. The first step is preparing this text.
The system splits sentences and breaks sentences into individual words or tokens. The word “New York” might be kept together as a single token because it is a location. Punctuation is separated. Special characters are handled appropriately. The text “John Smith’s company” becomes a sequence of tokens that the model can process.
This might seem simple, but tokenization significantly impacts results. How the system handles contractions, hyphenated words, and special characters in different languages determines downstream accuracy.
Step Two: Numerical Representation
Machine learning models work with numbers, not words. The system converts each token into a numerical vector that captures semantic meaning. Modern systems use word embeddings or contextual embeddings (like BERT) that represent each word not just by its identity but by its context in the sentence.
The word “bank” in “river bank” gets a different numerical representation than “bank” in “bank account” because context matters. This contextual representation is what makes modern NER so powerful compared to older pattern-matching approaches.
Step Three: Deep Learning Model Processing
The numerical representations flow through a deep learning model. The most common architecture in 2026 is transformer-based models (often BERT derivatives) because they excel at understanding context. The model processes the entire sequence of tokens simultaneously, understanding how each token relates to all other tokens in the sentence.
The model learns patterns during training. It learns that when certain linguistic and contextual patterns appear, they typically precede person names. Other patterns precede organization names. Other patterns precede locations or dates. The model identifies these patterns in your text.
Step Four: Entity Classification and Boundary Detection
For each token, the model outputs a prediction. The prediction says whether this token is the beginning of an entity, continuing an entity, or outside an entity. It also specifies what type of entity it is.
When the model processes “Mr. John Smith joined Apple Inc. on January 15, 2026”, it outputs classification for each token, identifying entity boundaries and types. The system then assembles these individual token predictions into structured entities.
Step Five: Post-Processing and Confidence Scoring
The raw predictions often need refinement. The system might apply rule-based corrections for common patterns. If it classified “U.S.A.” as three separate location entities instead of one, post-processing fixes this. The system outputs confidence scores indicating how certain it is about each classification.
Your application can then decide. If confidence exceeds 95%, automatically process. Between 80-95%, flag for human review. Below 80%, reject and require manual processing.
This entire pipeline executes in milliseconds on modern hardware, making real-time NER practical even for high-volume applications.
Deep Learning Architectures That Power Modern NER
Three main deep learning approaches dominate enterprise NER in 2026. Understanding when to use each helps you make the right technology choices.
Transformer-Based Models (BERT and Variants)
Transformers represent the current best practice for NER. Models like BERT, RoBERTa, and ALBERT were pre-trained on massive amounts of text, learning general language understanding. You then fine-tune these pre-trained models on your specific entity types.
Why transformers win: they understand bidirectional context (they look at words before and after simultaneously), they parallelize computation (making them fast), and they transfer learning effectively (pre-training on general text translates to your specific task).
A transformer-based NER system deployed by a legal tech company achieved 96.2% accuracy on contract entity extraction after fine-tuning on just 500 labeled examples. Traditional rule-based systems required thousands of hand-crafted rules and never exceeded 87% accuracy.
BiLSTM with CRF (Conditional Random Fields)
BiLSTMs are recurrent neural networks that process sequences. They are smaller and faster than transformers, making them practical for edge devices or resource-constrained environments.
A BiLSTM processes sequences in both directions (forward and backward), understanding context from both sides. The CRF layer on top makes globally optimal predictions by considering the sequence as a whole rather than predicting each token independently.
Why BiLSTMs still matter: they are faster and more efficient than transformers, they work well when you have limited training data (50-200 examples), and they are easier to understand and debug.
A customer service company uses BiLSTM-CRF models deployed on their servers because the 200ms response time requirement made transformer-based models too slow. The model provides 91% accuracy, sufficient for automated routing while catching 95% of high-priority issues.
Large Language Models and GPT-Based Approaches
GPT models and other large language models brought a new paradigm in 2026. Instead of fine-tuning pre-trained models, you can prompt GPT-4 or similar models to extract entities. “Extract all organizations mentioned in this text” becomes a natural language instruction.
Why GPT models offer advantages: they work across entity types without retraining, they handle context and ambiguity well, and they can follow complex instructions. The main drawback is cost and latency for high-volume applications.
A healthcare company uses GPT-based NER for complex clinical notes where domain-specific knowledge matters. For high-volume transaction monitoring in their banking division, they use smaller fine-tuned BERT models to control costs.
Making Your Choice
Choose based on your constraints: accuracy requirements (transformers are best), speed requirements (BiLSTM), cost sensitivity (smaller models), and available training data (GPT approaches need less).
Getting Named Entity Recognition Into Production: A Step-By-Step Guide
You understand the concepts. Now let us walk through actually implementing NER in your systems. Here’s a technical description of the production workflow:
- Data Preparation: Collect and preprocess your text data. Clean and normalize documents, handle encoding issues, and segment text into sentences and tokens. Quality data is essential for accurate entity extraction.
- Model Selection: Choose a suitable NER model based on your requirements. For general-purpose tasks, pre-trained transformer models (like BERT or RoBERTa) are effective. For domain-specific needs, consider models fine-tuned on relevant data or specialized architectures (e.g., BioBERT for medical text).
- Training and Fine-Tuning: If your domain requires custom entity types, label a representative dataset and fine-tune the model. Use transfer learning to adapt pre-trained models to your data. Evaluate performance using precision, recall, and F1 score.
- Deployment: Package the trained model as an API or integrate it into your application pipeline. Ensure the system can handle real-time or batch processing as needed. Monitor latency and throughput for production workloads.
- Post-Processing: Apply rule-based corrections, confidence thresholds, and human review queues for ambiguous cases. Structure the output for downstream systems (databases, dashboards, or workflow automation).
- Monitoring and Continuous Improvement: Track model performance in production. Set up feedback loops for human corrections and retrain periodically to adapt to evolving entity types and new data.
Real-World Use Case: Healthcare Records
A hospital automated entity extraction from clinical notes by labeling custom entity types, fine-tuning a BioBERT model, and deploying it as an API. This reduced manual extraction time from 8 minutes to 30 seconds per note, improved data quality, and saved millions annually. Human review was integrated for uncertain cases, and the system was retrained monthly to stay current.
Challenges You Will Encounter and Solutions That Work
Implementing NER at scale reveals practical challenges that textbooks do not mention.
Challenge 1: Domain-Specific Entities
Pre-trained models know common entities like PERSON, LOCATION, ORGANIZATION. But what if you need to identify drug compounds, genetic sequences, mineral types, or software frameworks?
Solution: Fine-tune models on domain-specific data. The pharmaceutical company that processes clinical research papers fine-tunes on 300 examples of labeled protein names, drug compounds, and genetic markers. The model learns these domain-specific patterns. Cost is minimal: 30 minutes of GPU time.
Challenge 2: Entity Ambiguity
The word “Python” is a programming language, a snake, and appears in multiple company names. Context determines meaning.
Solution: Modern transformers handle this well because they understand context. But when context is genuinely ambiguous, implement a confidence threshold and human review queue for borderline cases.
Challenge 3: Multilingual Challenges
Many enterprises operate globally. English NER does not work for Chinese, Arabic, Hindi, or other languages.
Solution: Hugging Face offers multilingual BERT. However, performance is lower than English. For critical multilingual processing, fine-tune separate models per language.
Challenge 4: Handling Low-Resource Languages
Languages with little online text have minimal training data for pre-trained models.
Solution: Transfer learning helps. Fine-tune a multilingual model on even 100 examples in your target language, and it often performs surprisingly well.
Challenge 5: Evolving Entity Types
Your entity types change. New product names emerge. New regulation categories appear. Your NER system must adapt.
Solution: Implement continuous learning. Set aside 5-10% of model predictions for human review monthly. Use this feedback to retrain monthly. Your model stays current.
Measuring What Matters: NER Performance Metrics
You deployed NER. Now how do you know if it is working well? Understanding performance metrics guides your optimization efforts.
Precision and Recall
Precision answers: of all the entities the model identified, what percentage were correct? Recall answers: of all the entities that actually existed in the text, what percentage did the model find?
Think of a security guard (the NER model) checking people into a building. High precision means the guard rarely lets in someone who does not belong. High recall means the guard rarely misses someone who should enter.
Most applications need both, but the priority depends on your use case. A compliance system needs high precision (false positives create expensive false alarms). A research system might tolerate lower precision if it needs high recall (missing an important paper is worse than reviewing one extra irrelevant paper).
Typical NER systems achieve 85-92% precision and recall on general English text. Specialized fine-tuned models reach 94-97% on narrow domains.
F1 Score
F1 combines precision and recall into a single metric. It is the harmonic mean: neither precision nor recall can dominate. Most papers report F1 scores.
The Accuracy Trap
Never judge NER by simple accuracy. If your text has 95 non-entity tokens and 5 entity tokens, a naive model that says “everything is a non-entity” achieves 95% accuracy while being useless.
Always use precision, recall, and F1 score.
Real-World Performance Expectations
- On clean, well-formatted English text on standard entity types: expect 90-95% F1 with pre-trained models
- On domain-specific text with custom entity types: expect 85-92% F1 with fine-tuned models
- On multilingual or low-resource language text: expect 75-88% F1
If your actual results are significantly lower, you likely have a data quality issue (messy input) or your entity definitions are ambiguous.
Integrating NER Into Your Business Systems
Understanding the technology means nothing if you cannot integrate it into your actual business processes. Let me explain the architectural patterns that work.
Real-Time Processing Pattern
You have high-volume incoming data that requires immediate processing. Chat support messages. Customer emails. Transaction descriptions. Real-time monitoring feeds.
Architecture: Deploy a containerized NER service. Users send text to an API endpoint. The service returns entities within 100-500 milliseconds. You process results immediately: auto-route, alert, enrich, or store.
Cost: A containerized NER service processes approximately 100,000 documents daily on a single GPU (AWS g4dn.xlarge instance) for approximately $0.52 daily. Cost per million documents processed is approximately $5.
Batch Processing Pattern
You have large volumes of historical documents or periodic batches. Monthly reports. End-of-quarter document processing. Research data sets. Archive processing.
Architecture: Submit batch jobs that process thousands of documents in parallel. Store results in a database. Run overnight or during off-peak hours to optimize costs.
Cost: Using spot instances and efficient batching, processing 1 million documents costs approximately $2-4.
Hybrid Pattern
Critical transactions require immediate processing and better accuracy. Routine transactions can be batch-processed. You implement both patterns.
Real-time path: Chat support (real-time, lower accuracy acceptable)
Batch path: Monthly compliance reports (batch-processed, higher accuracy required)
This hybrid approach balances cost, accuracy, and responsiveness.
The Future of Named Entity Recognition: What is Coming
As we navigate 2026, NER is evolving in several important directions.
Multimodal Entity Recognition
Extracting entities from combined text, images, and videos simultaneously. A system looks at a product photo, reads the product description, and watches an advertisement video to identify mentioned entities. This is beginning to appear in enterprise content platforms.
Few-Shot and Zero-Shot NER
Systems that work effectively with zero or very few labeled examples by learning from natural language descriptions. “Identify all mentions of our product competitors” requires no labeled examples. The system understands from the instruction alone.
Contextual and Dynamic Entities
Entities that change meaning based on context. “Apple” in the context of fruit versus technology. Systems that dynamically understand context are advancing.
Ethical and Responsible NER
Understanding that NER systems can reveal sensitive personal information. The field is developing approaches to redact sensitive entities, audit for bias, and ensure privacy.
The field continues to advance rapidly. The good news: the foundational approaches you implement today will remain relevant.
Share Your Challenges in Comments
Have you encountered entity recognition challenges? Are you struggling with a specific domain or language? Share your specific use case in the comments.
Explore Related Reading
You may have read our earlier deep-dive on Sentiment Analysis, which focuses on understanding emotion in text. NER and sentiment analysis are complementary technologies. Where sentiment analysis tells you how customers feel, NER tells you what they are talking about. Together they provide complete customer understanding.
Key Takeaways
- Named Entity Recognition is production-ready technology. It is no longer advanced research. Thousands of production systems across every industry deploy NER daily.
- The business case is compelling. 85% reduction in manual processing time, 92% improvement in compliance accuracy, and foundation for intelligent automation systems.
- The technology is accessible. Open-source implementations like spaCy are free. Pre-trained models from Hugging Face are free. You can implement production NER without purchasing expensive software.
- The challenge is integration, not technology. Understanding when to use NER, what entity types to extract, and how to integrate results into your business processes is the real challenge. The framework in this article provides that understanding.
- Start small and iterate. Experiment with pre-trained models. Move to fine-tuned models only if necessary. Integrate progressively. Measure impact at each step. This systematic approach moves you from interest to implementation to business value faster.
Technical Resources
- spaCy NER Guide: spacy.io/usage/linguistic-features#named-entities
- Hugging Face Token Classification: huggingface.co/docs/transformers/tasks/token_classification
- BioBERT for Biomedical NER: github.com/dmis-lab/biobert
- Prodigy for Data Labeling: prodi.gy
- NERVARC Dataset for Benchmarking: Available through major NLP dataset repositories