In deep learning, architectures and optimizers get the spotlight, but data quality and data pipelines determine whether a system actually works in production. In enterprise deployments, I have seen state-of-the-art backbones underperform because the training set encoded leakage, label noise, silent duplicates, or shifting feature definitions across source systems.
Well-prepared data improves not only offline accuracy but also training stability (fewer exploding/vanishing gradients due to scale issues), convergence speed (better-conditioned inputs), and generalization (reduced spurious correlations). If you are also working on enterprise text generation, you will recognize the same theme: model behavior is downstream of the dataset. (Related: Text generation in artificial intelligence: how enterprises are turning language into a strategic asset.)
If you are building generative AI (LLMs, RAG, or fine-tuning) the stakes are even higher: preprocessing decisions (tokenization, deduplication, PII redaction, and quality filtering) directly shape a model’s loss landscape and downstream behaviors (hallucination rate, toxicity, privacy leakage, and factuality). This post focuses on the end-to-end data preparation pipeline with enterprise-ready, technically grounded practices.
How to use this guide: Skim the steps first, then deep-dive where it matches your modality (tabular, text, vision) and constraints (latency, privacy, labeling budget).
- If you are new to production ML: focus on Steps 2, 8, and 11 (cleaning, splitting, validation).
- If you are building LLM/RAG: pay extra attention to deduplication, PII redaction, document scoring, and retrieval-time monitoring.
- If your metrics look “too good”: run leakage unit tests (duplicates across splits, target leakage, preprocessing fit on full data).
- At enterprise scale: prioritize versioning, lineage, and SLAs so you can reproduce runs and debug incidents.
The Role of Data in Deep Learning Systems
Deep learning models require vast amounts of data. However, raw data from enterprise systems is often messy, inconsistent, and incomplete.
- Missing values and sparse fields
- Duplicate entities (records, users, sessions) and near-duplicates
- Inconsistent schemas and formats (units, time zones, encodings)
- Noise and outliers (sensor glitches, bot traffic, extreme amounts)
- Unstructured modalities (text, images, audio) with variable quality
- Label noise, weak supervision, and annotation drift over time
- Data leakage risks (future information bleeding into training features)
In practice, teams often spend the majority of effort on data work (ingestion, cleaning, labeling, and validation) rather than model architecture. You can quantify this by tracking time-to-train-ready dataset, the number of failed training runs due to data issues, and the fraction of compute wasted on malformed batches or corrupted samples.
Without proper preprocessing, even the most advanced neural networks can produce unreliable results.
What is Data Preparation and Preprocessing
Data preparation is the process of collecting, cleaning, and structuring raw data into a usable format. Preprocessing is a subset that focuses on transforming data into a form suitable for machine learning algorithms.
Together, they ensure that data is consistent, meaningful, and optimized for learning.
- Data collection and ingestion (batch/stream)
- Data cleaning and validation (schema + content checks)
- Data transformation (encoding, scaling, normalization)
- Feature engineering or representation learning inputs
- Labeling strategy (gold labels, weak labels, active learning)
- Dataset splitting and evaluation design (avoid leakage; mimic production)
Infographic: End-to-End Data Preparation Pipeline
Imagine a flow that begins with raw enterprise data and ends with optimized datasets ready for training. Each step adds value and reduces uncertainty in the model output.
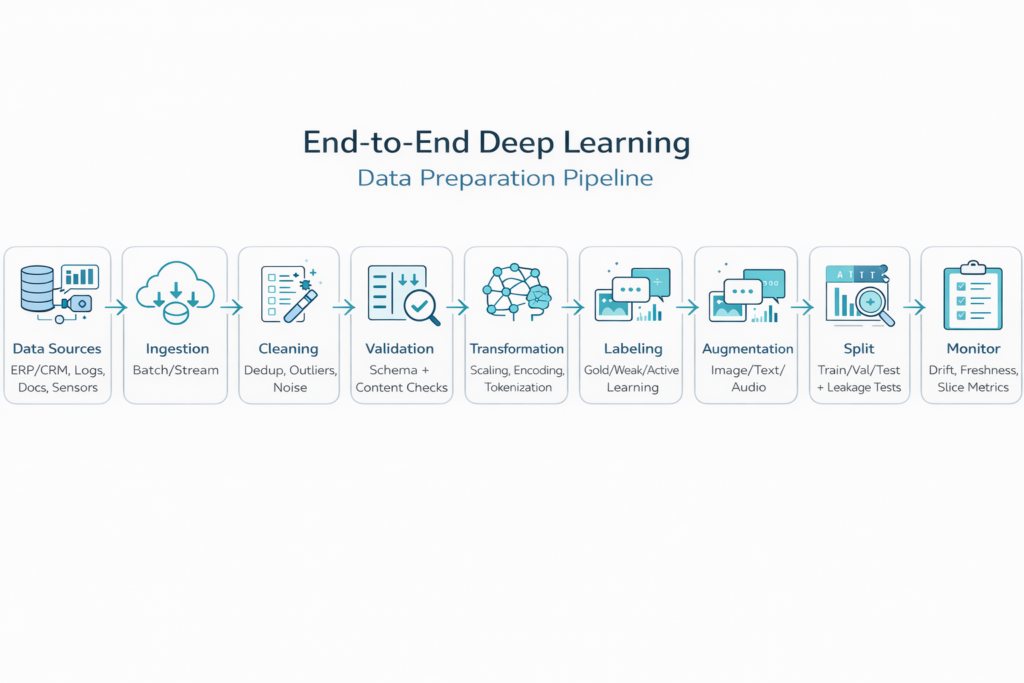
Step 1: Data Collection in Modern Enterprises
- Transactional systems (ERP/CRM), event logs, clickstreams
- Customer support channels (chat, email, call transcripts)
- IoT/sensor telemetry (often high-frequency and noisy)
- Document repositories and knowledge bases (PDFs, wikis)
- Third-party data feeds (with licensing/compliance constraints)
For example, in customer support AI systems, data may include chat logs, emails, and voice transcripts. This is directly connected to text generation systems discussed in the previous article.
The challenge is not just collecting data, but ensuring its relevance and quality.
- Adopt data contracts (schema, units, acceptable ranges) between producers and ML consumers
- Enforce governance: access control, PII handling, retention, and audit trails
- Track lineage (source → transformations → dataset version) for reproducibility and incident response
- Instrument ingestion with quality signals: missingness rates, null bursts, late-arriving data, and freshness SLAs
Step 2: Data Cleaning, Removing Noise and Inconsistencies
Raw data is rarely clean. Cleaning involves identifying and fixing errors.
- Handle missingness (MCAR/MAR/MNAR assumptions matter)
- Deduplicate exact and near-duplicate records (hashing, MinHash/LSH for text)
- Normalize formats (time zones, locale, encodings, categorical vocabularies)
- Detect outliers (robust z-scores, IQR rules, isolation forests) and decide: cap, remove, or model explicitly
- Remove or quarantine corrupted samples (e.g., unreadable images, invalid JSON)
Real-world example: In a retail recommendation system, duplicate customer entries can lead to incorrect personalization. Cleaning ensures each customer profile is unique and accurate.
Impact: Clean data improves model accuracy by up to 30 percent in some use cases.
Step 3: Handling Missing Data Strategically
Missing data is one of the most common issues in enterprise datasets.
- Drop incomplete records only when missingness is random and sample size remains sufficient
- Impute with simple statistics (mean/median/mode) for baselines and robust pipelines
- Model-based imputation (kNN, MICE, autoencoders) when relationships across fields are informative
- Add missingness indicators so the model can learn “missing” as a signal
- Prevent leakage: fit imputers on training data only, then apply to validation/test
Example: In healthcare AI systems, missing patient data cannot simply be removed. Intelligent imputation techniques are used to preserve critical insights.
Step 4: Data Transformation for Model Readiness
Deep learning models require numerical input. Transformation converts raw data into machine-readable formats.
- Encode categorical variables: one-hot for low cardinality; learned embeddings for high cardinality
- Normalize/standardize numeric features (z-score) and consider robust scaling for heavy tails
- Apply log/Box-Cox transforms for skewed distributions (e.g., spend, latency)
- Text preprocessing: Unicode normalization, language detection, tokenization strategy (BPE/WordPiece), deduplication, and profanity/PII filtering
- Image/audio: resizing, normalization, sample-rate alignment, and channel handling
Example: Customer data like location or product category must be converted into numerical representations before training a model.
Why this matters: Unscaled data can bias the model and slow down training.
Step 5: Feature Engineering, The Hidden Power
Feature engineering is where domain expertise meets AI.
It involves creating new variables that help the model learn better patterns.
- Aggregate purchase history into RFM features (recency, frequency, monetary value) or customer lifetime value proxies
- Derive sentiment, topics, or intent labels from text (rule-based weak supervision as a bootstrap)
- Create time-based features: time-since-last-event, rolling windows, seasonality flags
- Graph features: degrees, PageRank, and neighborhood aggregation for entity interactions
In natural language systems, feature engineering plays a key role in transforming raw text into meaningful embeddings.
This directly connects to enterprise text generation systems where semantic understanding drives value.
Infographic: Feature Engineering Impact
Feature engineering can significantly boost model performance without changing the algorithm.
Step 6: Data Labeling for Supervised Learning
Supervised deep learning requires labeled data.
Labeling involves assigning correct outputs to input data.
- Spam vs. not spam for email classification
- Bounding boxes / masks for object detection and segmentation
- NER tags and sentiment labels for NLP tasks
- Preference data (chosen vs. rejected responses) for alignment and RLHF-style training
- Manual labeling is slow and expensive; rare classes amplify cost
- Inconsistent guidelines lead to label noise, measure inter-annotator agreement (e.g., Cohen’s κ) where applicable
- Concept/label drift: what “fraud” or “priority ticket” means can change over time
- Use assisted labeling (model-in-the-loop) with human verification
- Apply active learning to prioritize uncertain/high-value samples
- Bootstrap with weak supervision (heuristics, rules, distant labels) and improve iteratively
- Run labeling QA: gold sets, spot checks, and disagreement adjudication
Step 7: Data Augmentation for Better Generalization
Data augmentation increases dataset size by creating variations of existing data.
- Images: flips/rotations/crops, color jitter, MixUp/CutMix (task dependent)
- Text: paraphrasing, back-translation, span masking (avoid changing label semantics)
- Audio: time stretching, pitch shift, background noise injection
- Tabular: noise injection and synthetic sampling (use caution—can distort correlations)
Example: In computer vision systems, augmenting images helps models recognize objects under changes in orientation, lighting, and viewpoint.
Impact: Improves robustness and reduces overfitting, provided augmentations preserve label semantics (for example, do not flip digits if the class depends on orientation).
Step 8: Splitting Data for Training and Evaluation
Proper data splitting ensures unbiased model evaluation.
- Train: fit model parameters
- Validation: tune hyperparameters / early stopping / model selection
- Test: final, unbiased estimate after decisions are locked
- Prevent data leakage: transformations, scaling, and imputers must be fit on train only
- Use stratified splits for classification to preserve class ratios
- For temporal problems, prefer time-based splits (train on past → test on future)
- For entity-centric data, use group splits (e.g., by user/customer) to avoid memorization
- Add “leakage unit tests”: search for duplicated IDs/text across splits and suspiciously high offline metrics
In enterprise systems, improper splitting can lead to overly optimistic results that fail in production.
Step 9: Handling Imbalanced Data
Many real-world datasets are imbalanced.
Example: Fraud detection where fraudulent transactions are rare.
- Resampling: oversample minority (or use SMOTE variants) and/or undersample majority
- Cost-sensitive learning: class-weighted or focal loss
- Threshold tuning and calibration (Platt/Isotonic) based on business costs
- Evaluate with imbalanced-aware metrics: PR-AUC, F1, recall@precision, and cost curves (not accuracy)
Impact: Improves detection of rare but critical events.
Step 10: Automating Data Pipelines
Modern AI systems rely on automated data pipelines.
- Orchestration: scheduled ETL/ELT and streaming ingestion for freshness SLAs
- Data versioning and immutable dataset snapshots for reproducibility
- Continuous data validation (schema tests, distribution checks, anomaly alerts)
- Feature stores (when appropriate) to keep online/offline feature parity
Benefits: scalability, consistency, and faster deployment.
Automation is essential for enterprises handling large-scale AI workloads.
Step 11: Data Validation, Testing, and Monitoring (Often the Missing Layer)
Treat data pipelines like software: add automated tests, quality gates, and observability. This is how you prevent silent failures such as a new category value breaking an embedding lookup, a changed unit (ms vs s) destabilizing training, or a skewed sampling job inflating offline performance.
- Schema checks: required columns, types, allowed enums, and constraints
- Content checks: missingness, range rules, string length, invalid tokens, image decode success rate
- Distribution checks: compare train vs serving distributions (e.g., PSI, KL divergence) to detect shift
- Label checks: label prevalence over time, noise audits, and delayed-label leakage
- Slice metrics: evaluate by segment (region, device, customer tier) to catch hidden failures
- Monitoring: data freshness, drift alerts, and feedback loops once in production
Real-World Use Cases
- AI in Customer Experience
Prepared data enables personalized recommendations, chatbots, and sentiment analysis. Key enablers include entity resolution (deduping customers), consistent event semantics, and text normalization; measure impact with offline ranking metrics (NDCG/Recall@K) and online A/B tests.
- Financial Fraud Detection
Clean and balanced datasets help detect anomalies in real time. Use time-based splits, cost-sensitive losses, and PR-AUC/recall@precision to reflect business risk; monitor drift because fraud patterns evolve quickly.
- Healthcare Diagnostics
Preprocessed medical data improves accuracy in disease prediction. Handle missingness explicitly, validate label quality, and prioritize calibration (reliable probabilities) and slice-based evaluation to reduce harmful failure modes across patient subgroups.
- Generative AI Systems
As discussed in the previous article, text generation systems rely heavily on clean and structured training data. For RAG, data preparation extends to document selection, chunking strategy, metadata quality, and deduplication; evaluate with retrieval metrics (Recall@K) plus task-level factuality and hallucination checks.
Key Insights for Executives
- Data is a strategic asset: quality, access, and governance determine which AI use cases are feasible
- Track KPIs: time-to-train-ready, failed training runs due to data, label cost per 1k samples, and drift incidents
- Investing in pipelines often yields higher ROI than incremental model tuning once you’re past a baseline
- Automation + validation reduces operational risk (privacy leakage, biased outcomes, and production regressions)
Across industry, postmortems commonly attribute AI project delays to data access, quality, labeling, and governance—not model code. The practical takeaway: treat data pipelines as first-class products with owners, SLAs, and measurable reliability.
Common Mistakes to Avoid
- Ignoring data quality early (then paying for it during model debugging)
- Leakage via preprocessing fitted on full data, target leakage features, or duplicates across splits
- Overfitting through non-representative evaluation (random splits for time-series problems)
- No data governance (PII exposure, unclear retention, and weak access controls)
- Manual pipelines that do not scale and cannot be reproduced
Future Trends in Data Preparation
- Data-centric AI practices: systematic dataset improvement, not just architecture iteration
- Automated quality filtering for LLM training data (deduplication, toxicity/PII filters, document scoring)
- Synthetic data for privacy or rare events, paired with strict validation to avoid mode collapse and bias amplification
- Real-time and near-real-time preprocessing with streaming feature computation
- Tighter integration with MLOps: dataset versioning, reproducible training, and drift monitoring
Enterprises are moving towards data-centric AI, where improving data quality is more important than tweaking algorithms.
This article explains how structured and well-prepared data enables powerful text generation systems in enterprises.
High-performing deep learning systems are rarely “model-only” wins, they are pipeline wins. When you invest in deduplication, leakage prevention, modality-appropriate transformations, and continuous validation/monitoring, you reduce wasted training cycles and ship models that behave predictably in production. Use the steps above as a checklist, and iterate on the dataset with the same rigor you apply to architecture and hyperparameters.