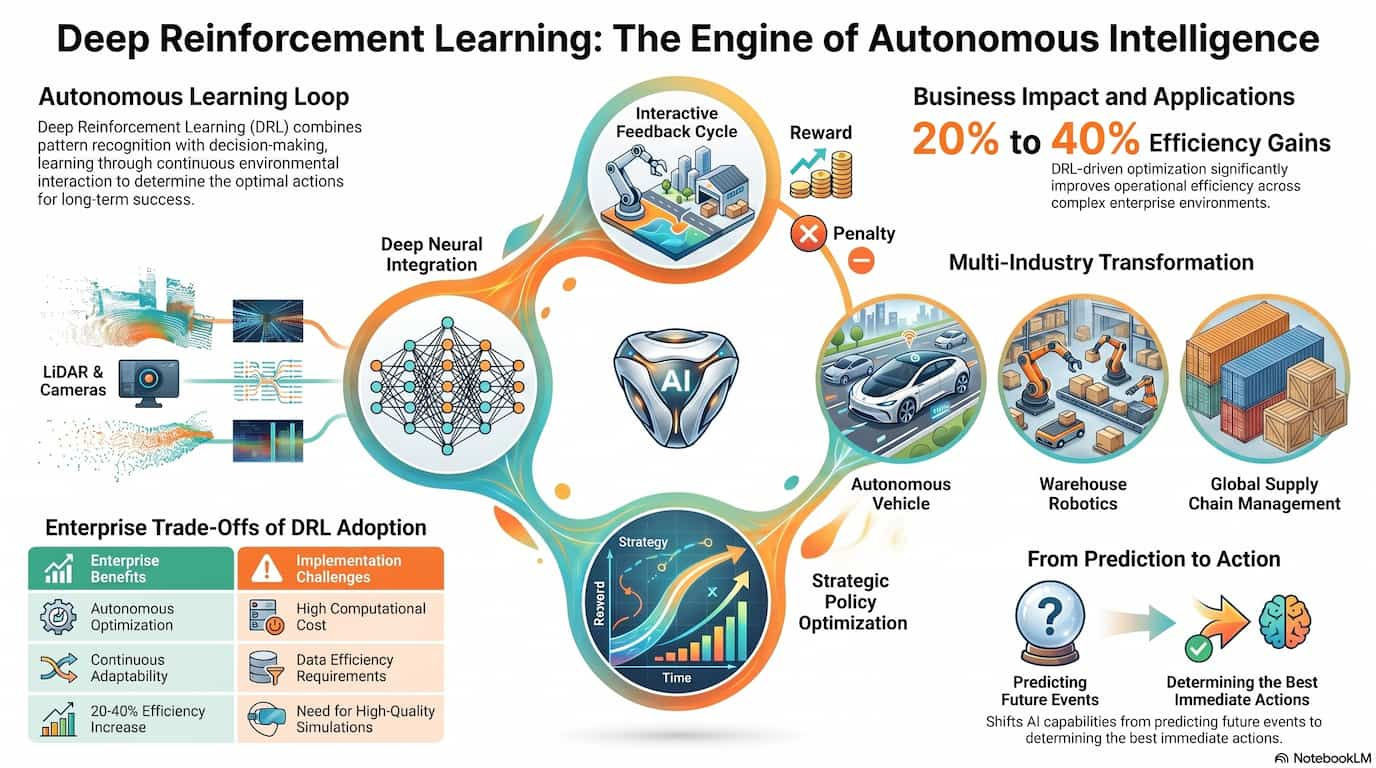
Artificial Intelligence Deep Learning Emerging Technologies Generative AI Machine Learning Deep Reinforcement Learning: The Technology Powering Autonomous AI Decision MakingArtificial Intelligence is rapidly evolving from systems that simply analyze data to systems that can June 15, 2026June 15, 2026
Artificial Intelligence Deep Learning Generative AI Deep Learning in Practice: Data Preparation and Preprocessing for Real-World AI SuccessIn deep learning, architectures and optimizers get the spotlight, but data quality and data pipelines March 21, 2026
Artificial Intelligence Deep Learning Generative AI Image Generation and Style Transfer in Artificial Intelligence, From Creative Automation to Enterprise-Scale IntelligenceArtificial Intelligence has moved far beyond pattern recognition and prediction. Today, AI systems are capable January 19, 2026January 19, 2026
Agentic WorkFlows Artificial Intelligence Generative AI Uncategorized Top Emerging AI Platforms & Tools in 2025: What They Do and Why They MatterThe AI ecosystem in 2025 is evolving faster than ever. From agentic AI workflows to December 1, 2025
AI Models Artificial Intelligence Generative AI Machine Learning Pytorch AI-Driven Customer Service in Cable Gateways: Enhancing User ExperienceCustomer expectations are constantly evolving, and businesses must adapt to meet these demands by leveraging January 19, 2025January 19, 2025
Artificial Intelligence Generative AI What if Your Notes Could Talk Back? Meet NotebookLMIn a world where information is power, being able to effectively manage your notes is January 11, 2025January 11, 2025
Artificial Intelligence Generative AI Integrating AI into Embedded Devices: Opportunities and ChallengesIntroduction In the rapidly evolving world of technology, Artificial Intelligence (AI) is providing us a December 22, 2024
Artificial Intelligence Generative AI Machine Learning Learn About Different Types of Machine Learning: Supervised, Unsupervised, and Reinforcement LearningMachine learning is transforming industries, enhancing products, and making significant advancements in technology. To fully June 26, 2024May 26, 2024
Artificial Intelligence Generative AI Dive into AI: A Closer Look at “Artificial Intelligence: A Modern Approach” by Stuart Russell and Peter Norvig (Chapters 1-2)As I start my journey to master Generative AI, I have decided to start with May 26, 2024May 26, 2024