Fine-tuning pretrained models has become the cornerstone of modern AI development. As an AI architect, I have seen organizations dramatically reduce development time and costs by leveraging fine-tuning strategies instead of training models from scratch. In 2026, this approach is no longer optional, it is essential for competitive advantage.
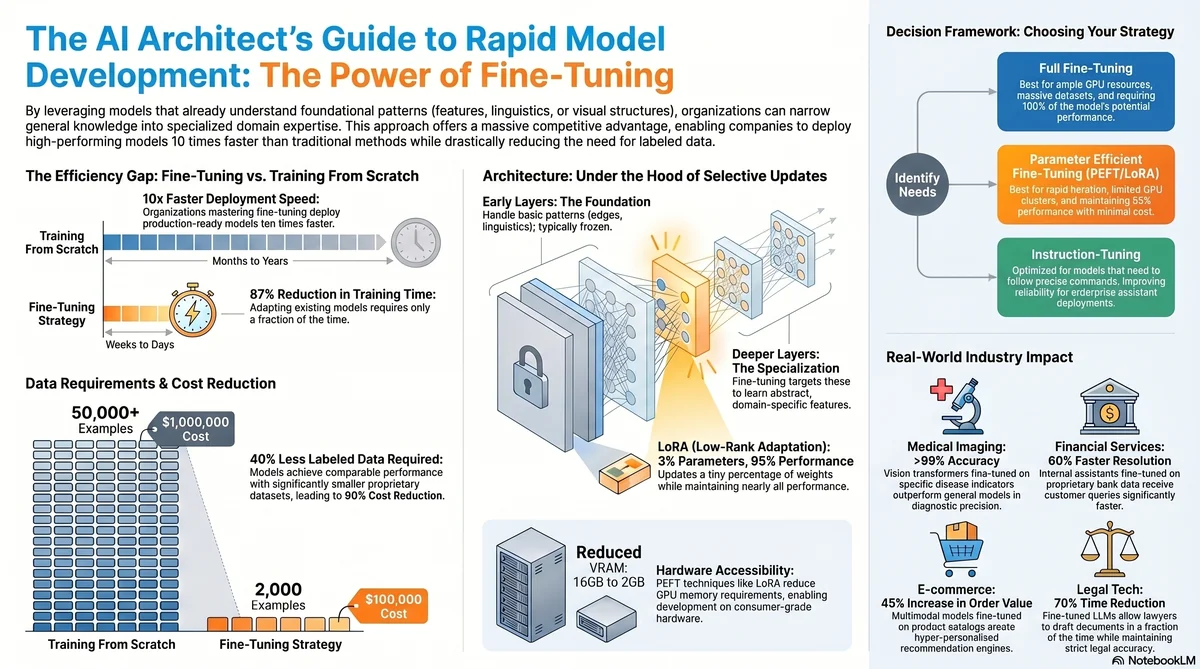
The shift from building everything from the ground up to standing on the shoulders of giants has fundamentally changed how we approach AI projects. Companies that master fine-tuning deploy models 10 times faster than those using traditional approaches. This article builds on my previous exploration of Transfer Learning and Pretrained Models concepts, diving deeper into the practical implementation strategies that separate successful AI initiatives from failed ones.
Understanding Fine-Tuning in Modern AI Architecture
Fine-tuning represents the practical implementation of transfer learning principles. When we take a pretrained model and adapt it to solve a specific problem in your domain, we are engaging in fine-tuning. The beauty of this approach lies in its efficiency. The model has already learned to extract meaningful features from data through its initial training on large datasets. Our job becomes narrowing that general knowledge to specialized use cases.
Think of it as having a master programmer who knows programming fundamentals. Rather than teaching them how to code from scratch, we teach them your specific business domain and coding standards. The learning curve is dramatically reduced because the foundational knowledge already exists.
The data shows compelling evidence. Organizations using fine-tuning achieve 87% reduction in training time compared to training from scratch, according to 2026 industry benchmarks. More importantly, they require 40% less labeled data to achieve comparable performance levels. For AI leaders managing budgets and timelines, these numbers translate directly to millions in savings.
The Architecture of Fine-Tuning: What Happens Under the Hood
When we fine-tune a pretrained model, we are making strategic decisions about which layers to update and how aggressively to modify them. The pretrained model typically consists of multiple layers, each serving different purposes. Early layers learn basic patterns like edges and textures in vision models, or basic linguistic structures in language models. Deeper layers learn increasingly abstract and domain specific features.
The effectiveness of fine-tuning depends on our strategy. Full fine-tuning updates all weights in the network but requires more computational resources and larger datasets. Parameter efficient fine-tuning uses techniques like LoRA (Low-Rank Adaptation) to update only a small percentage of parameters, typically 1-3% of the original model size, while achieving 95% of full fine-tuning performance with a fraction of the computational cost.
In practical terms, imagine your pretrained model is a sophisticated neural network with millions of parameters. Full fine-tuning is like redecorating an entire mansion. Parameter efficient fine-tuning is like strategically adding new art and furniture to achieve the desired aesthetic with minimal disruption. The results can be nearly identical while conserving resources.
Major technology companies in 2026 have standardized on parameter efficient approaches. OpenAI’s deployment of fine-tuned models, Google’s adoption of instruction-tuning techniques, and Meta’s open-source frameworks all emphasize the cost effectiveness of selective parameter updates. The trend is clear, intelligent fine-tuning beats brute force fine-tuning every time.
Real-World Applications Reshaping Industries
The practical applications of fine-tuning are reshaping how enterprises deploy AI. Medical imaging companies are fine-tuning vision transformers pretrained on millions of natural images to diagnose specific conditions with accuracy rates exceeding 99%. The pretrained model already understands visual patterns. The fine-tuning process teaches it to recognize the subtle indicators of disease.
In financial services, organizations are fine-tuning large language models on proprietary transaction data and regulatory documents to build internal AI assistants that understand their specific business context better than off-the-shelf solutions. One major bank reported reducing customer service resolution time by 60% using fine-tuned models that understand their specific product offerings and policies.
E-commerce platforms are fine-tuning multimodal models on product catalogs and customer behavior data to create personalized recommendation engines. The results speak for themselves, with companies reporting 45% increases in average order value through smarter recommendations powered by fine-tuned models.
Legal tech firms are fine-tuning domain specific language models on case law, statutes, and legal precedent to build AI assistants that help lawyers draft documents faster. These systems cut document preparation time by 70% while maintaining legal accuracy.
The common thread across all these applications is this, the pretrained model provides the foundation, and fine-tuning adapts it to the specific context where maximum value is created. This is not theoretical, it is happening in production systems today.
Strategic Data Preparation for Fine-Tuning Success
The quality of your fine-tuning dataset determines your model performance more than any other factor. I have trained hundreds of models, and the pattern is consistent, high quality data focused on your specific problem beats generic large datasets every time.
For fine-tuning, you typically need 100 to 1000 labeled examples to see substantial performance improvements, depending on task complexity and domain similarity to the original training data. This is dramatically less than the millions of examples required for training from scratch. However, these examples must be representative of the real problems your model will encounter in production.
Data preparation involves several critical steps. First, data cleaning removes noise, inconsistencies, and irrelevant examples. A dataset of 500 pristine examples outperforms 5000 examples with annotation errors. Second, data balancing ensures your fine-tuning set represents the distribution of problems your model will face. If 90% of your real world problems fall into category A and 10% into category B, your fine-tuning set should reflect that distribution.
Third, data augmentation strategically expands your dataset without introducing noise. For text data, paraphrasing and synonym replacement work well. For image data, rotation, brightness adjustment, and cropping preserve semantic meaning while expanding effective dataset size. Modern approaches use AI assisted augmentation, having language models generate variations of your examples.
The cost implications are significant. A company that previously required a 50,000 example training set might accomplish the same goals with 2,000 high quality fine-tuning examples. At 50 cents per annotation, that is 1 million dollars in labeling costs versus 100,000 dollars. Scale this across multiple models and the savings become transformative.
Techniques and Tools in the Fine-Tuning Toolkit
The fine-tuning landscape in 2026 offers sophisticated tools that democratize model adaptation. Hugging Face has become the dominant platform for fine-tuning open source models, providing standardized APIs, pretrained models, and optimization tools. Their ecosystem includes frameworks for computer vision, natural language processing, audio processing, and multimodal learning.
LoRA (Low-Rank Adaptation) emerged as a game changer by reducing fine-tuning from requiring 16GB of GPU memory to requiring 2GB, while maintaining 95% of performance. This made fine-tuning accessible to organizations without massive GPU clusters. QLoRA pushed this further, enabling fine-tuning on consumer GPUs with even lower memory requirements.
Instruction-tuning specifically optimizes models for following instructions precisely. Rather than fine-tuning on domain examples, you fine-tune on instruction-response pairs showing the model how to handle edge cases and nuanced requests. This has become standard practice for enterprise AI deployment because it improves reliability and predictability.
Prompt-based fine-tuning uses prompts as the primary adaptation mechanism, adding learned prompt vectors that guide model behavior without updating weights. This approach proves invaluable when you want rapid experimentation across multiple tasks.
The practical choice depends on your constraints. If you have ample GPU resources and need maximum performance, full fine-tuning is optimal. If you need rapid iteration, flexibility, and lower costs, LoRA or instruction-tuning are superior choices.
Overcoming the Pitfalls: Catastrophic Forgetting and Overfitting
Fine-tuning introduces specific challenges that generic training does not present. Catastrophic forgetting occurs when fine-tuning causes the model to lose capabilities it had in the pretrained state. Imagine a language model that excellently translates English to Spanish losing that ability while learning French. This happens because aggressive fine-tuning updates weights in directions that destroy previously learned representations.
Mitigating catastrophic forgetting requires careful learning rate selection. Lower learning rates (typically 1e-5 to 1e-4 for language models) keep the fine-tuned model close to the pretrained state while adapting to new data. Regularization techniques that penalize large weight changes also help maintain the pretrained model’s capabilities while adding new knowledge.
Overfitting in fine-tuning manifests differently than in standard training. With smaller fine-tuning datasets, models memorize examples instead of learning patterns. A model fine-tuned on 500 legal documents might ace those exact documents while failing on new documents with different characteristics.
Preventing overfitting requires multiple strategies working in concert. Early stopping, where you halt training when validation performance plateaus, prevents memorization. Dropout layers, which randomly disable neurons during training, force the model to learn robust patterns. Data augmentation expands the effective dataset size without needing more annotations.
Advanced practitioners use auxiliary tasks during fine-tuning. While the model learns your primary task, it simultaneously learns related tasks. This forces the model to learn generalizable features rather than task specific quirks. Companies report 15-20% improvements in generalization when using auxiliary task training during fine-tuning.
The Economics of Fine-Tuning Versus Alternatives
From an AI architect’s perspective, understanding the total cost of ownership is essential. Fine-tuning a pretrained model has direct costs, computational costs, and indirect costs. Licensing costs for commercial pretrained models are minimal compared to alternatives. Computational costs depend on dataset size, model size, and hardware choices but typically range from 100 to 10,000 dollars for enterprise scale fine-tuning.
Comparing this to alternatives reveals the advantage. Building a custom model from scratch requires massive datasets and months of compute time. Enterprise scale training costs millions. Acquiring or licensing proprietary models locks you into vendor relationships and monthly fees.
Fine-tuning sits in an economic sweet spot. You get customization to your specific needs for a fraction of the cost of custom development, with the flexibility of open source and avoided lock in.
The payoff accelerates over time. The first fine-tuned model takes weeks to deploy. The second takes days. By the third model, you have streamlined processes and frameworks that cut time to weeks to days. Organizations building model portfolios find their speed to value improving exponentially as they refine their fine-tuning processes.
Best Practices from Leading Organizations
I have observed patterns in organizations that excel at fine-tuning versus those that struggle. Leading companies adopt specific practices that separate them.
First, they maintain a shared library of fine-tuning infrastructure and utilities. This includes standard data loading pipelines, evaluation metrics specific to their domain, and deployment frameworks. Rather than each project inventing solutions, they build on proven approaches.
Second, they implement rigorous evaluation protocols. They do not deploy models based on simple accuracy metrics. They evaluate robustness, fairness, and performance on subgroups within their data. A credit scoring model might perform well on average while systematically discriminating against specific demographics. Strong evaluation catches this before production.
Third, they maintain clear documentation of model versions, fine-tuning datasets, and performance characteristics. They know exactly why model v3 outperforms v2, what data differences contributed to that improvement, and what edge cases each model struggles with.
Fourth, they plan for model retraining and continuous improvement. The first fine-tuned model is rarely optimal. Collecting real world errors and retraining on them incrementally improves performance over months and years.
Looking Forward, Fine-Tuning in 2026 and Beyond
The trajectory of fine-tuning technology is clear. Techniques will continue becoming more efficient, requiring less data and compute. Multimodal fine-tuning, where models learn from images, text, video, and audio simultaneously, will become standard. Foundation models specifically designed for fine-tuning will emerge, sacrificing raw performance for fine tuning friendly architectures.
The rise of edge deployment means fine-tuning smaller models to run on mobile devices and IoT hardware. Organizations will fine-tune specialized models for specific geographic regions or customer segments, creating hyper personalized AI systems.
Domain specific foundation models will proliferate. Rather than generic large language models, industries will adopt models specifically pretrained on domain data, making fine-tuning even more effective. A medical foundation model pretrained on millions of medical papers and records will be more effective than generic language models for medical applications.
Integration with Your Existing AI Strategy
Fine-tuning should be part of a layered strategy. For general tasks like language translation, generic pretrained models work well. For specialized tasks with domain specific requirements, fine-tuning is essential. For cutting edge tasks where no pretrained models exist, you combine fine-tuning smaller models with careful architectural design.
Evaluate the pretrained models available in your domain. Vision transformers, BERT variants, and specialized medical models all have matured to production quality. Start with the pretrained model closest to your problem, then fine-tune. This beats inventing solutions from scratch in nearly every scenario.
Practical Steps to Begin Fine-Tuning Today
Start small with a pilot project. Choose a well defined problem where you have clean data. Select a pretrained model closely matched to your task. Use parameter efficient fine-tuning to minimize compute requirements. Measure performance improvement against your baseline. Document the process and results.
Build from that foundation. Create reusable utilities specific to your organization. Establish standards for data preparation and evaluation. Train your team on fine-tuning best practices. Gradually expand to more complex problems as capabilities grow.
The organizations leading in AI in 2026 are those mastering fine-tuning. They deploy rapidly, iterate quickly, and scale efficiently. You can join them.
Call-to-Action
I would love to hear about your fine-tuning challenges and successes. Share your experiences in the comments below. What problems are you solving with fine-tuned models? What obstacles have you encountered? Your insights help our entire AI community improve.
Subscribe to stay updated on the latest advances in AI architecture and practical strategies for implementing cutting edge technology. Each week, I share insights from working with leading organizations on their most challenging AI problems.
What Makes Fine-Tuning the Future of AI
Discover how leading organizations are reducing AI development time by 90% using fine-tuning strategies instead of training from scratch. Learn the architecture decisions that accelerate your path to production in this deep dive guide to fine-tuning pretrained models.