Voice is becoming the most natural interface between humans and machines. From smart assistants to real-time transcription tools, speech technologies are reshaping how enterprises operate, communicate, and scale intelligence. Deep learning for natural language processing plays a pivotal role in enabling machines to understand and generate human speech with remarkable accuracy.
In my previous article on deep learning for sequential data and time series forecasting, I discussed how neural networks learn patterns over time to predict future outcomes. Speech is also sequential data, but it introduces additional complexity such as variability in tone, accents, noise, and context. This article builds on that foundation and dives deeper into how deep learning models handle speech recognition and synthesis.
This post is written for architects, engineers, and decision-makers who want to understand both the technical depth and business value of speech AI systems.
Why Speech Recognition and Synthesis Matter Today
Speech is one of the fastest-growing interfaces in enterprise AI adoption. According to industry data:
- Over 50 percent of digital interactions are expected to be voice-based
- Speech recognition systems now achieve near human-level accuracy in controlled environments
- Customer service automation using voice AI reduces operational costs by up to 30 percent
- The global speech AI market is projected to exceed 50 billion dollars within the next few years
These numbers reflect a broader shift toward conversational AI systems that are intuitive, scalable, and accessible.
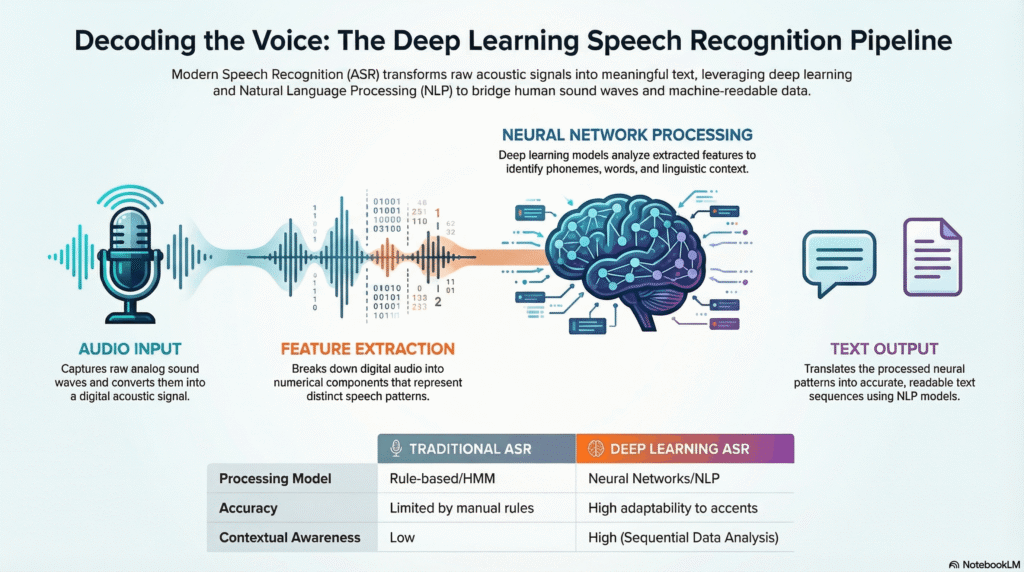
Understanding Speech Recognition in NLP
Speech recognition, also known as automatic speech recognition, converts spoken language into text. It is a multi-stage deep learning pipeline that processes raw audio signals and transforms them into structured language.
Key Components of Speech Recognition
- Audio Signal Processing
The system captures raw audio and converts it into spectrograms or feature representations such as Mel-frequency cepstral coefficients. These features help models interpret frequency and time variations. - Acoustic Modeling
Deep neural networks map audio features to phonemes or subword units. Models like convolutional neural networks and recurrent neural networks are commonly used. - Language Modeling
Language models ensure the predicted text is coherent and grammatically correct by learning probabilities of word sequences. - Decoding
The final stage combines acoustic and language models to generate the most probable transcription.
Evolution of Deep Learning Models in Speech Recognition
Traditional Models
Earlier systems relied on Hidden Markov Models combined with Gaussian Mixture Models. These approaches required heavy feature engineering and struggled with variability.
Deep Learning Breakthrough
Deep learning transformed speech recognition by enabling end-to-end training. Key architectures include:
- Recurrent Neural Networks and Long Short-Term Memory networks for sequential dependencies
- Convolutional Neural Networks for extracting spatial features from spectrograms
- Transformer-based architectures that capture long-range dependencies efficiently
Modern systems such as end-to-end transformer models eliminate the need for separate acoustic and language models.
Real World Use Cases of Speech Recognition
Enterprise Customer Support
- AI-powered voice bots handle customer queries, reducing wait times and improving satisfaction. These systems can process thousands of calls simultaneously.
Healthcare Documentation
- Doctors use speech-to-text systems to dictate notes, improving efficiency and reducing administrative workload.
Financial Services
- Voice authentication systems enhance security by analyzing speech patterns.
Accessibility
- Speech recognition empowers individuals with disabilities by enabling voice-controlled systems.
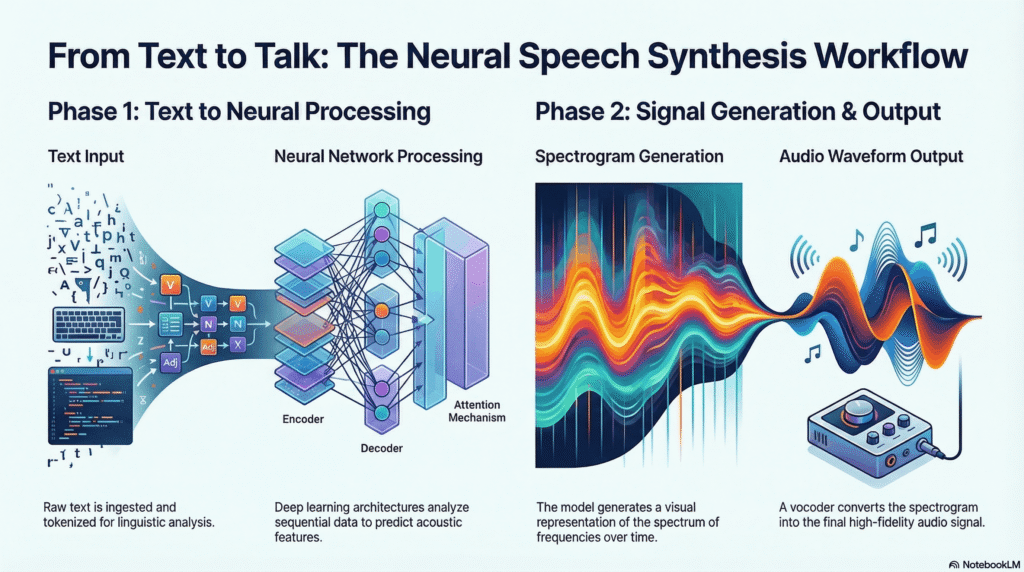
Speech Synthesis: Giving Voice to Machines
Speech synthesis, also known as text-to-speech, converts text into human-like speech. It enables machines to communicate naturally with users.
Key Components of Speech Synthesis
- Text Analysis
The system processes input text, identifying structure, punctuation, and pronunciation rules. - Acoustic Modeling
Neural networks generate intermediate representations of speech such as spectrograms. - Waveform Generation
The final stage converts spectrograms into audible waveforms using vocoders.
Deep Learning Models for Speech Synthesis
WaveNet
- WaveNet introduced a breakthrough by generating raw audio waveforms with high fidelity. It significantly improved naturalness in generated speech.
Tacotron
- Tacotron models convert text directly into spectrograms, enabling end-to-end speech synthesis.
FastSpeech
- FastSpeech improves speed and scalability, making it suitable for real-time applications.
Transformer-Based Models
- Transformers enable parallel processing and improved contextual understanding, making them ideal for large-scale speech systems.
Key Challenges in Speech AI
Despite advancements, several challenges remain:
Variability in Speech
- Accents, dialects, and speaking styles introduce complexity. Models must generalize across diverse datasets.
Background Noise
- Real-world environments are noisy. Noise robustness remains a critical challenge.
Data Requirements
- Deep learning models require massive labeled datasets, which can be expensive to obtain.
Real-Time Processing
- Latency is crucial in applications such as voice assistants and live transcription.
Linking Back to Sequential Data Learning
In my previous article on deep learning for sequential data and time series forecasting, I explained how models learn temporal dependencies. Speech processing builds directly on these principles:
- Audio signals are time-dependent sequences
- Context across time impacts meaning
- Models must retain memory of previous inputs
You can read that article here: https://muralimarimekala.com/2026/03/29/deep-learning-for-sequential-data-time-series-analysis-and-forecasting/
Understanding time series modeling provides a strong foundation for mastering speech AI systems.
Industry Trends in Speech AI
Conversational AI Platforms
- Organizations are integrating speech recognition and synthesis into unified conversational platforms.
Multilingual Models
- Modern systems support multiple languages, enabling global scalability.
Edge Deployment
- Speech models are increasingly deployed on edge devices, reducing latency and improving privacy.
Generative AI Integration
- Speech synthesis is now combined with generative AI to create dynamic, context-aware responses.

Architecture Blueprint for Enterprise Speech Systems
A scalable speech AI system typically includes:
- Data ingestion pipelines for audio streams
- Preprocessing layers for noise reduction
- Deep learning models for recognition and synthesis
- APIs for integration with applications
- Monitoring systems for performance and accuracy
Cloud platforms play a major role in scaling these systems across geographies and workloads.
Best Practices for Implementing Speech AI
- Invest in High-Quality Data
Diverse datasets improve model robustness - Optimize for Latency
Use model compression and edge deployment where possible - Focus on User Experience
Naturalness and accuracy are critical for adoption - Ensure Privacy and Security
Voice data is sensitive and must be protected - Continuously Monitor and Improve
Deploy feedback loops to refine models over time
Business Impact and ROI
Organizations adopting speech AI report:
- Faster customer interactions
- Reduced operational costs
- Improved accessibility and inclusivity
- Enhanced user engagement
Speech technologies are no longer experimental. They are core components of digital transformation strategies.
Future of Speech Recognition and Synthesis
The future is moving toward fully conversational AI systems that understand context, emotion, and intent. Key developments include:
- Emotion-aware speech synthesis
- Real-time multilingual translation
- Personalized voice assistants
- Integration with augmented and virtual reality
Speech will become the primary interface for interacting with intelligent systems.
If you are building AI-driven products or leading digital transformation initiatives, now is the time to invest in speech technologies. Start experimenting with speech recognition and synthesis models, integrate them into your workflows, and measure their impact.
I encourage you to share your thoughts in the comments, discuss your use cases, and subscribe to stay updated on the latest advancements in AI and deep learning.