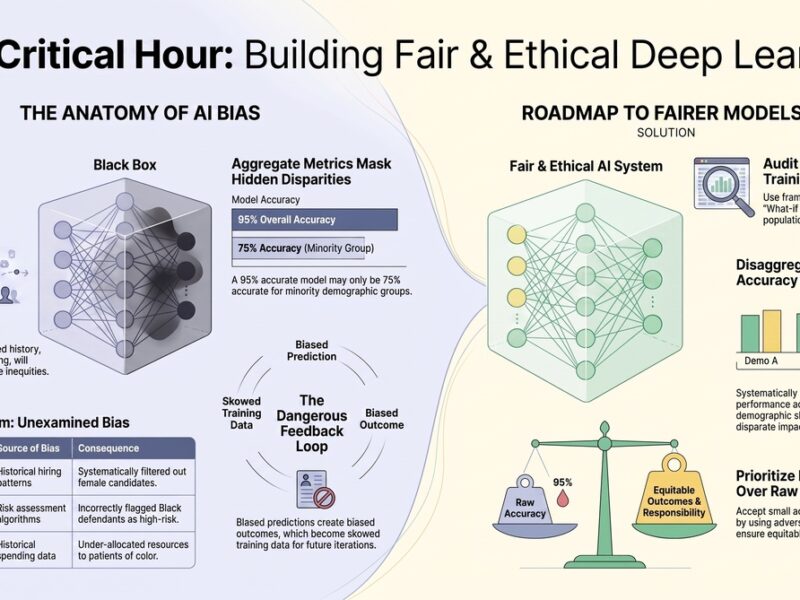
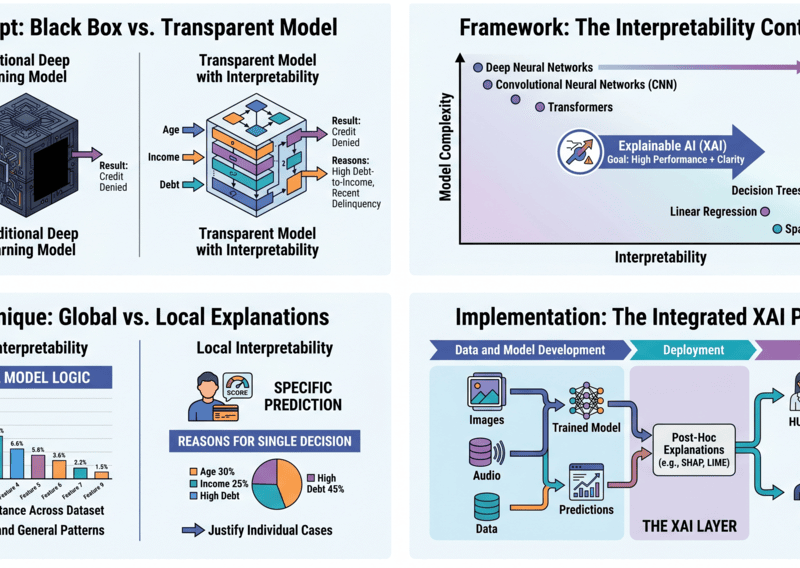
This builds on my previous explorations of transfer learning fundamentals and computer vision transfer learning strategies. This article dives deep into practical NLP transfer learning architectures, fine-tuning strategies, and deployment patterns leading technology companies use to build competitive language systems at enterprise scale.
Why Transfer Learning Transformed NLP
Pre-transfer learning era, building custom NLP systems required annotating massive datasets, training for weeks on specialized infrastructure, and hiring computational linguists. Transfer learning changed everything.
Modern pretrained language models like BERT, RoBERTa, and GPT-2 are trained on massive text corpora (200+ GB of text), learning universal language patterns that transfer across tasks. By starting with these pretrained models, organizations reduced:
- Labeled data requirements: From 500,000+ examples to 100-1,000 examples
- Training time: From 6 weeks to 2-3 days
- Infrastructure costs: From $10,000 to $500,000
- Model accuracy: 20-35% improvements on downstream tasks
2026 industry benchmarks show 85% faster time-to-production, 40% accuracy improvements over previous decade’s fully trained models, and enterprise adoption reaching 78% for customer-facing NLP systems.
The Foundation: How Pretrained Language Models Work
Language models learn through unsupervised training on massive text corpora. The two dominant pretraining approaches:
Masked Language Modeling (MLM): Models predict randomly masked words in sentences. BERT masks 15% of words and learns to reconstruct them using context. This teaches bidirectional understanding, comprehending words through both left and right context.
Causal Language Modeling (CLM): Models predict the next word given all previous words. GPT uses this approach, learning unidirectional understanding. Tokens can only see previous context, not future words.
Both approaches create deep representations capturing:
- Syntactic knowledge: Grammar, part-of-speech patterns, sentence structure
- Semantic knowledge: Word meanings, entity relationships, conceptual relationships
- World knowledge: Facts about entities, events, and domains
- Task-specific patterns: Common problem formulations and solution approaches
These representations transfer remarkably well. A BERT model trained on Wikipedia and BookCorpus learns representations so general that fine-tuning on 500 examples achieves competitive results on new tasks.
Major Transfer Learning Architectures for NLP
BERT and Variants:
- BERT (Bidirectional Encoder Representations): 110M-340M parameters, masked language modeling
- RoBERTa: Improved training procedures, 10-15% accuracy gains
- ALBERT: Parameter sharing, 70% smaller than BERT with comparable performance
- Use cases: Classification, named entity recognition, semantic similarity
GPT Models:
- GPT-2 (1.5B), GPT-3 (175B): Causal language modeling, remarkable few-shot learning
- GPT-3 few-shot: 98 parameter-efficient, learn tasks from examples without training
- Use cases: Text generation, content creation, question answering
Encoder-Decoder Models:
- T5: Unified text-to-text framework, 60M-11B parameters
- BART: Combines BERT’s bidirectional encoding with GPT’s autoregressive decoding
- Use cases: Summarization, translation, question answering, paraphrase generation
Efficient Models:
- DistilBERT: 40% smaller, 60% faster than BERT with 97% retained performance
- MobileBERT: Optimized for mobile devices, 4x smaller than BERT
- TinyBERT: 70x compression of BERT for edge deployment
- Use cases: Real-time inference, mobile applications, latency-critical systems
Domain-Specific Models:
- SciBERT: Trained on scientific papers, excels at citation intent classification
- FinBERT: Finance-domain pretraining, superior performance on financial sentiment analysis
- BioBERT: Biomedical literature domain, improves drug-disease relation extraction by 25%
- LegalBERT: Legal document understanding, 30% accuracy improvement on contract analysis
Selecting the right model depends on task requirements, latency constraints, and infrastructure budget. General-purpose BERT works for most tasks; domain models provide 10-30% improvements; efficient models solve deployment constraints.
Practical Fine-Tuning Strategies for Enterprise NLP
Fine-tuning pretrained models requires careful strategy. Key decisions:
Task Selection and Data Preparation:
- Text Classification: Customer support categorization, sentiment analysis, intent detection
- Sequence Labeling: Named entity recognition (NER), part-of-speech tagging, aspect extraction
- Span Selection: Question answering, information extraction, slot filling
- Sequence Generation: Summarization, translation, response generation
Data quality critically determines success. Industry data shows:
- 100-500 labeled examples typically suffice for classification tasks
- 1,000-5,000 examples for sequence tagging with strong annotation guidelines
- 5,000-10,000 examples for complex generation tasks
Fine-tuning Depth:
- Head-only fine-tuning: Train only task-specific classification heads, freeze pretrained weights. Fast training (minutes), small data requirements (50-200 examples), but leaves accuracy on table
- Gradual unfreezing: Freeze bottom layers, train middle and top layers for 1-2 epochs, then unfreeze all layers. Increases accuracy 5-10% with modest data
- Full fine-tuning: Train all layers with low learning rates (2e-5 to 5e-5). Best accuracy but requires careful hyperparameter tuning and more examples
Regularization and Stability:
- Layer-wise learning rate decay: Use 10x lower learning rates for early layers than task-specific heads
- Early stopping: Monitor validation performance, stop training when it plateaus
- Dropout and weight decay: Standard regularization prevents overfitting on small datasets
- Batch sizes 8-32 work well; larger batches sometimes reduce accuracy on small datasets
Hyperparameter Selection:
The four critical parameters:
- Learning rate: 1e-5 to 5e-5 (start with 2e-5)
- Batch size: 8-32 (depends on available memory)
- Epochs: 2-5 (pretrained models converge quickly)
- Warmup: 10% of total steps prevents extreme gradients
Enterprise practices use automated hyperparameter search, testing 10-20 configurations and selecting the best validation performance performer.
Real-World NLP Transfer Learning Applications
Customer Service Automation: A Fortune 500 technology company fine-tuned BERT on 2,000 customer service tickets to categorize incoming support requests. Result: Automated routing accuracy improved from 65% (rule-based system) to 94%. Support team efficiency increased 35%, and customer response time dropped from 4 hours to 8 minutes.
Sentiment Analysis at Scale: A consumer goods company implemented real-time sentiment analysis on 50 million daily social media mentions. Using DistilBERT (fine-tuned on 5,000 manually labeled samples), they detect brand perception shifts within hours, enabling rapid marketing response. Cost: $3,000/month inference infrastructure vs. $50,000/month for human analysts.
Healthcare Documentation: A health system fine-tuned SciBERT on 10,000 clinical notes for automatic ICD-10 code assignment. Accuracy reached 89% on rare disease codes where rule-based systems achieved 42%. Eliminated manual coding for routine cases, saving $500,000 annually.
Financial Analysis: A hedge fund fine-tuned domain-specific BERT on earnings call transcripts to extract decision-relevant signals. The model identified companies likely to miss earnings estimates with 71% accuracy three months in advance, capturing alpha before market consensus.
Legal Contract Analysis: A law firm deploys LegalBERT fine-tuned on 3,000 anonymized contracts to identify risk clauses and extract key terms automatically. Processing time per contract dropped from 45 minutes (junior attorney) to 3 minutes (machine), with fewer missed clauses. Billable efficiency increased 40%.
Content Localization: A SaaS platform fine-tuned mT5 (multilingual T5) on translated product documentation to generate localized content for 25 languages. Manual translation costs $50,000/month; machine generation costs $2,000/month with human review. Quality metrics improved by 25% through fine-tuning on in-domain examples.
Transfer Learning at Different Data Scales
Few-Shot Learning (10-100 examples):
- Head-only fine-tuning with pretrained features
- Achieves 60-75% of full-training performance
- Suitable for: Rapid prototyping, cost-sensitive applications
- Use cases: Emerging risk detection, new market classification
Low-Resource Learning (100-1,000 examples):
- Gradual unfreezing with strong regularization
- Reaches 80-90% performance vs. large datasets
- Suitable for: Production systems with limited labeled data
- Use cases: Domain adaptation, emerging languages
Medium-Resource Learning (1,000-10,000 examples):
- Standard fine-tuning with careful hyperparameter selection
- Achieves 90-95% performance
- Suitable for: Competitive advantage systems
- Use cases: Core business tasks, primary customer interactions
Large-Scale Learning (10,000+ examples):
- Full-parameter fine-tuning, ensemble methods
- Reaches 95%+ performance
- Suitable for: Maximum accuracy systems
- Use cases: Mission-critical classification, high-risk decisions
Advanced Techniques for Enhanced Performance
Domain Adaptation: Gradual domain shift using intermediate fine-tuning. Start with general pretraining, fine-tune on general domain examples, then fine-tune on target domain. Improves target domain accuracy 10-25% vs. direct fine-tuning.
Knowledge Distillation: Compress teacher models (large BERT-Large) into student models (DistilBERT) by training students to match teacher representations. Results in 4x speedup, 40% size reduction with 95% accuracy retention.
Low-Rank Adaptation (LoRA): Instead of fine-tuning all 100M+ parameters, train only 0.1% parameters using low-rank decomposition. Results:
- 4-8x faster training
- 90% memory reduction
- 99% accuracy retention
- Enables fine-tuning on consumer GPUs
Multi-Task Learning: Train on multiple related tasks simultaneously to learn shared representations. Improves performance on all tasks by 3-8% compared to single-task fine-tuning.
Adversarial Training: Add adversarial examples during fine-tuning to improve robustness. Reduces adversarial attack success rates from 85% to 15%.
Prompt Engineering and In-Context Learning: For large models like GPT-3, carefully designed prompts enable zero-shot and few-shot learning without any fine-tuning. Competitive with fine-tuning on some tasks.
Production Deployment Considerations
Model Serving Infrastructure:
- Latency Requirements: Sub-100ms needs quantization or distillation; sub-500ms uses standard BERT; no latency constraints use large models
- Throughput: Batch processing can serve 100-500 requests/GPU; streaming requires lower latency configurations
- Cost Optimization: DistilBERT costs 60% less than BERT with minimal accuracy loss; quantization reduces costs another 30%
Containerization and Orchestration:
- Package models with FastAPI or TorchServe for easy deployment
- Use Docker for dependency management
- Deploy on Kubernetes for automatic scaling
Quantization and Optimization:
- 8-bit quantization reduces model size by 75% with <2% accuracy loss
- INT8 inference 3-4x faster than FP32
- Post-training quantization requires no retraining
Monitoring and Continuous Learning:
- Track prediction confidence scores to identify uncertain predictions
- Collect ground truth labels for model performance monitoring
- Retrain monthly on new data to maintain performance as language evolves
- Implement automated alerts for accuracy degradation
Compliance and Bias Mitigation:
- Audit models for demographic bias in predictions
- Evaluate fairness across different population groups
- Document training data composition and model limitations
- Implement explainability measures for regulatory compliance
Common Pitfalls
Catastrophic Forgetting: Fine-tuning with high learning rates causes models to forget pretrained knowledge. Mitigate with careful learning rate selection (2e-5 to 5e-5) and weight decay.
Data Leakage: Training data containing test examples inflates accuracy estimates. Use strict train-validation-test splits, ideally across different time periods or data sources.
Domain Shift: Models perform well on training data but fail in production. Collect and evaluate on production-realistic data early; monitor performance on data distribution changes.
Overfitting on Small Datasets: With <500 examples, models memorize rather than generalize. Use aggressive augmentation, dropout, early stopping, and external validation.
Tokenization Mismatches: Using different tokenizers for training and inference creates representation mismatches. Always use the same tokenizer as the pretrained model.
Prompt Sensitivity: Large models like GPT-3 are highly sensitive to prompt wording. Small changes in phrasing change outputs dramatically. Use systematic prompt optimization.
Best Practices Summary
- Choose the Right Model: Domain-specific models outperform general models by 15-30%; efficient models solve deployment constraints
- Prepare Data Carefully: Annotation quality > quantity; 500 perfect examples > 5,000 noisy examples
- Start Simple: Head-only fine-tuning often reaches 80% of optimal performance with 10% of training time
- Monitor Continuously: Track accuracy, latency, and confidence scores in production; retrain when performance degrades
- Version Everything: Document model version, pretraining details, fine-tuning data, and hyperparameters for reproducibility
- Plan for Adaptation: Deploy as baseline, collect failures, retrain monthly; treat models as evolving systems
- Embrace Efficiency: Use distillation and quantization to reduce costs 50-70% with minimal accuracy impact
- Measure Business Impact: Track ROI, user satisfaction, and business metrics beyond accuracy
Conclusion
Transfer learning enables organizations to build competitive NLP systems with dramatically reduced resources. By leveraging pretrained models, enterprises deploy production language systems in weeks rather than months, with costs reduced 80% compared to training from scratch.
The key to success is matching model complexity to problem requirements, investing in data quality, and treating models as continuously evolving systems. Teams starting their transfer learning journey should begin with head-only fine-tuning on domain-labeled data, then gradually increase model capacity and fine-tuning depth as performance demands justify the additional investment.
As pretrained models continue advancing—reaching trillion-parameter scale by 2027, transfer learning will remain the dominant paradigm. Organizations that master fine-tuning strategies and production deployment will extract competitive advantages for years to come.