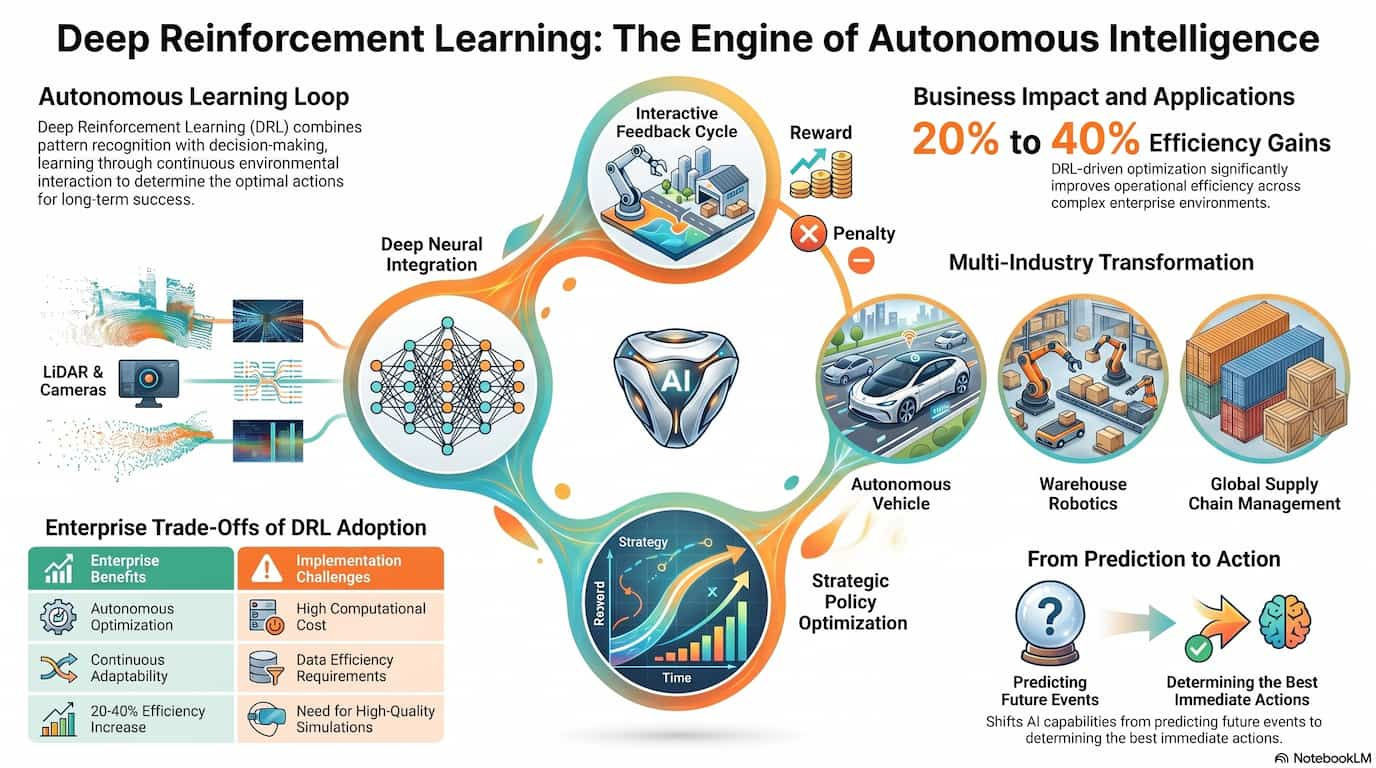
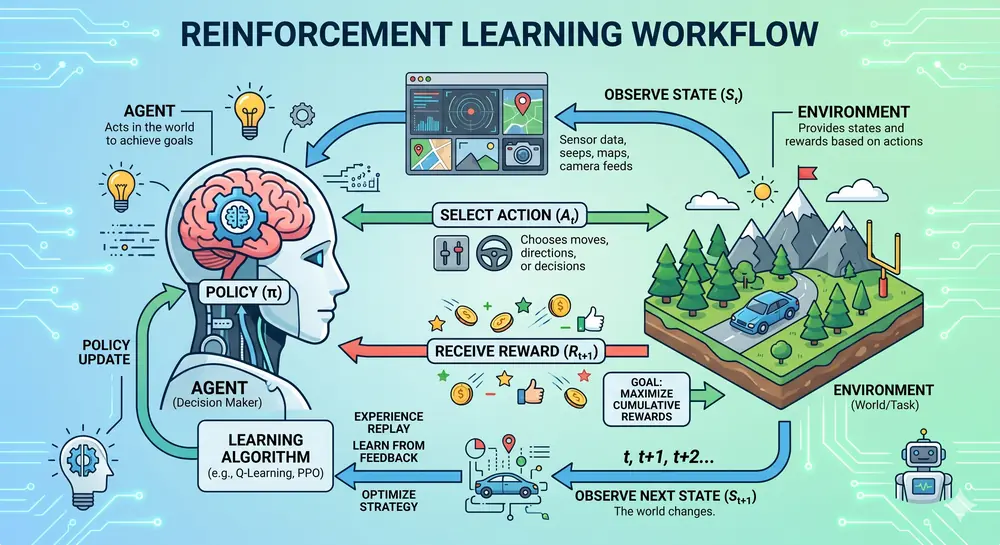
Learn how reinforcement learning and sequential deep learning drive autonomous systems, recommendations, and business intelligence. Real-world applications for enterprises.
Learn how deep learning models like LSTMs and Transformers generate music from sequential data, with practical use cases across media, gaming, and content.
Comprehensive guide to machine translation technology in 2026. Learn how enterprises implement real-time, batch, and hybrid translation systems with proven architectures and metrics.