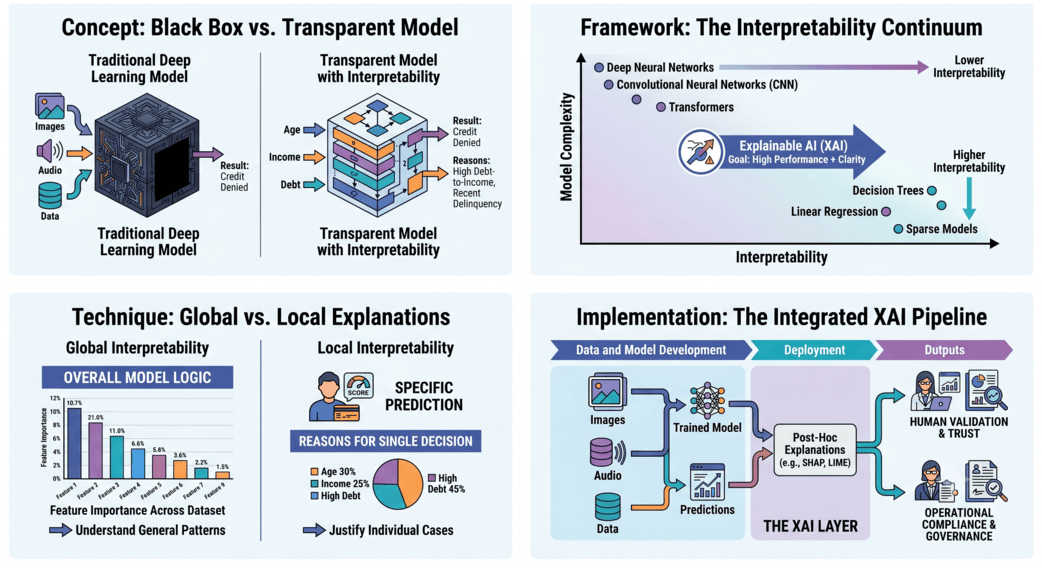
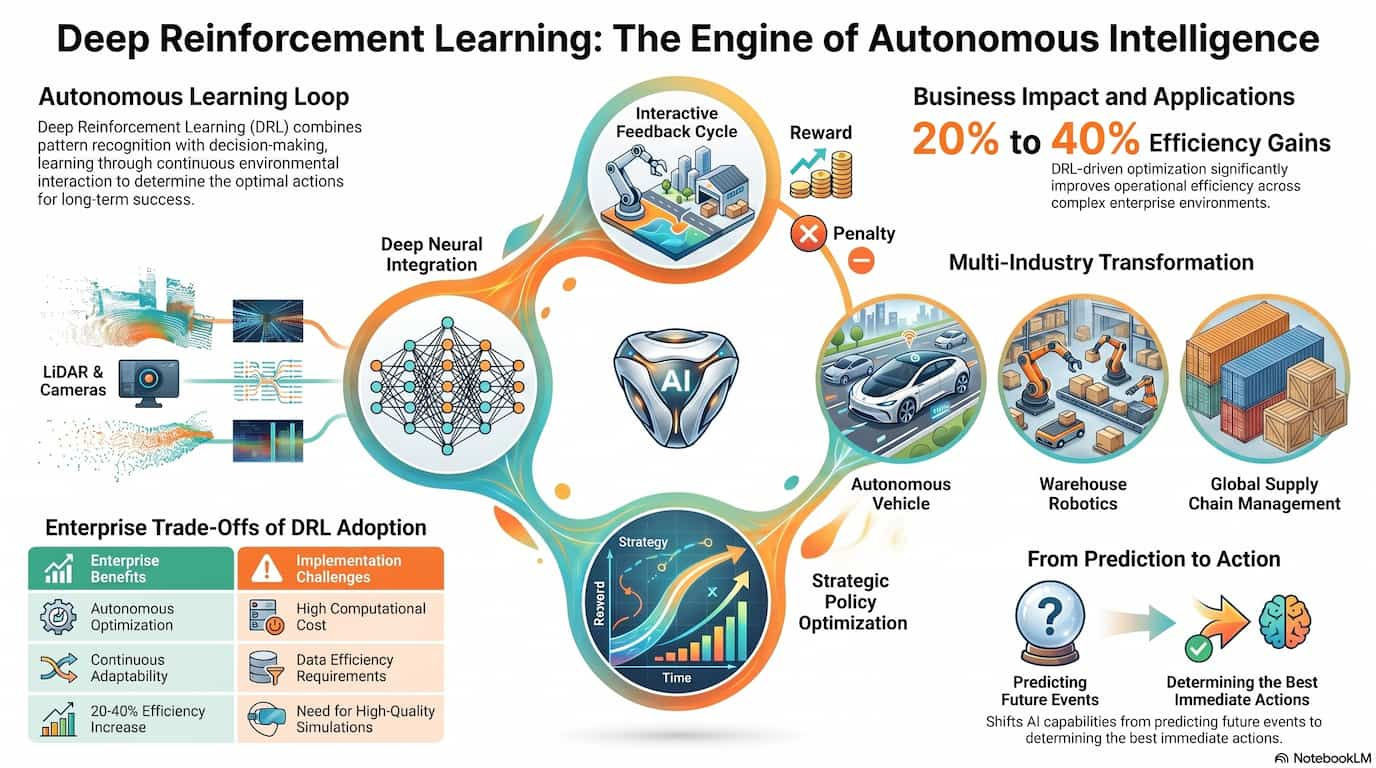
Learn how deep learning models like LSTMs and Transformers generate music from sequential data, with practical use cases across media, gaming, and content.
Master Named Entity Recognition in enterprise deep learning. Learn how companies automate data extraction, compliance, and intelligent systems with practical NER implementation strategies.