The rapid acceleration of enterprise artificial intelligence has brought us to a critical crossroads. Deep learning models now drive automated credit scoring, medical imaging diagnostics, autonomous navigation, and predictive maintenance pipelines. Yet, as these neural networks grow more sophisticated, they also become more opaque. For engineering architects and technology leaders, this opacity introduces an unacceptable layer of risk. Treating advanced AI as a pure black box is no longer a viable engineering or business strategy.
Enterprise systems require visibility into how decisions are reached. Explainable AI, commonly known as XAI, and model interpretability have transitioned from academic sub-fields into foundational requirements for modern enterprise architecture. Building trust, ensuring compliance, and optimizing performance depend entirely on our ability to look beneath the hood of complex deep learning structures.
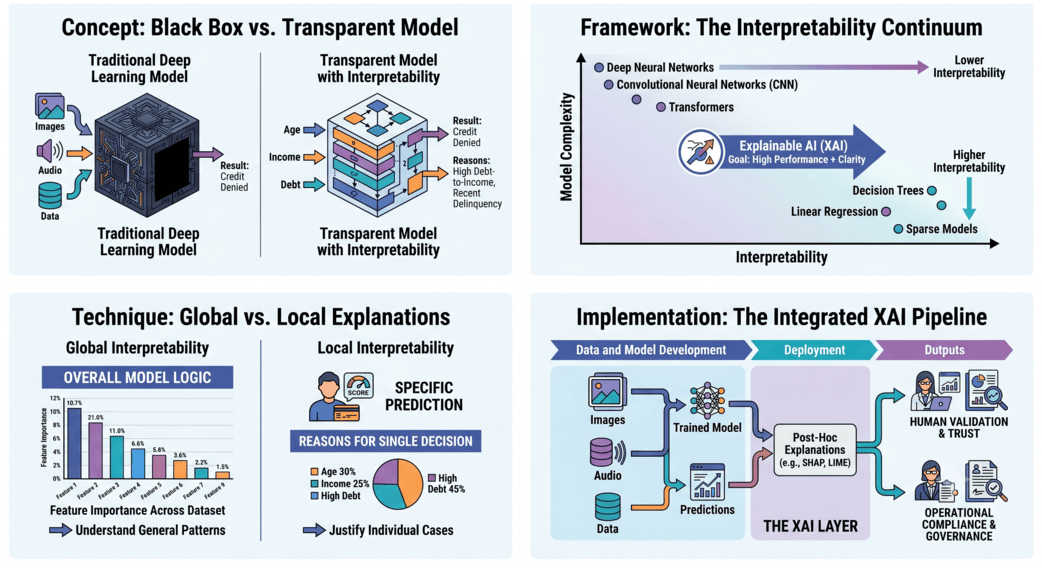
The Operational Imperative for Interpretability
Deep learning excels at identifying intricate, non-linear relationships within vast datasets. By processing information through hundreds of hidden layers, a deep neural network can outperform traditional statistical models across numerous benchmarks. However, this high performance often comes at the expense of clarity. A standard linear regression model provides explicit coefficients for each input variable, making it naturally interpretable. In contrast, a deep transformer network or a convolutional neural network relies on millions of shifting weights distributed across a dense matrix, rendering the exact decision path invisible to the naked eye.
This visibility gap creates unique operational hazards. When a deep learning system operates entirely as a black box, verifying the underlying logic behind any individual output becomes nearly impossible. If a model predicts a structural failure in a factory component or flags a financial transaction as fraudulent, domain experts need to know the specific features that triggered that determination. Without interpretability, debugging a misclassifying model degrades into a costly guessing game, leaving organizations vulnerable to hidden data drift, edge case failures, and underlying bias.
Bridging the Gap: From Autonomous Decisions to Transparent Logic
To fully appreciate the urgency of Explainable AI, we can observe how it naturally complements other advanced paradigms in modern system architecture. In my previous article analyzing Deep Reinforcement Learning: The Technology Powering Autonomous AI Decision-Making, we explored how autonomous agents learn optimal behavioral policies through continuous environmental interaction and feedback loops. While deep reinforcement learning empowers systems to execute highly dynamic actions in real time, pairing that autonomy with robust interpretability frameworks ensures that those autonomous decisions remain fully auditable, safe, and aligned with human intent.
When an autonomous system operates in a high-stakes ecosystem, knowing the final action is only half the battle. Architects and engineers must verify the underlying justification. By integrating interpretability mechanisms directly into your broader AI deployment strategy, you ensure that every autonomous breakthrough remains securely anchored by a traceable, logical foundation.
Core Methodologies: How Explainable AI Works
Achieving clarity in deep learning requires a structured combination of distinct methodologies. Data architects typically classify interpretability approaches into two primary dimensions, which are intrinsic versus post-hoc, and global versus local.
Intrinsic versus Post-Hoc Interpretability
Intrinsic interpretability refers to designing models that are inherently transparent from inception. These include simpler architectures such as decision trees, generalized additive models, and sparse linear frameworks. While highly explainable, intrinsic models can fall short when processing highly unstructured data streams like raw audio, video, or massive natural language corpora.
Post-hoc interpretability accepts the complex, black-box nature of deep neural networks and applies secondary analytical techniques to extract explanations after the model has completed its training phase. Post-hoc tools reverse-engineer the model behavior, translating matrix math into actionable visual maps, feature importance charts, or natural language summaries that human operators can easily comprehend.
Global versus Local Explanations
Global interpretability focuses on explaining the overarching logic of the complete model across an entire dataset. It answers the question, what general features matter most to the network when it makes decisions across all historical inputs? Global explanations assist architects in validating that the system has internalized correct macro-level concepts rather than memorizing noise.
Local interpretability looks at a single, isolated prediction. If an AI system denies a specific loan application, local interpretability isolates the exact variables, such as debt-to-income ratio or recent credit inquiries, that drove that particular outcome. Local explanations are essential for customer service teams, compliance auditors, and field engineers who must justify individual automated responses.
Key Technical Frameworks Powering Modern XAI
Several powerful algorithmic frameworks have become industry standards for delivering post-hoc, local explanations for deep learning systems. Implementing these tools within your MLOps pipeline transforms raw model outputs into structured, defensible data insights.
SHAP (SHapley Additive exPlanations)
Based on cooperative game theory, SHAP calculates the optimal game-theoretic equilibrium to assign credit to each feature for a given model outcome. It measures how much the prediction changes when a specific feature is present versus when it is excluded, distributing the impact fairly among all inputs.
SHAP provides a mathematically rigorous foundation that guarantees consistency and local accuracy. This makes it exceptionally valuable for structured data models operating in highly regulated spaces like insurance underwriting and algorithmic trading, where mathematically defensible explanations are non-negotiable.
LIME (Local Interpretable Model-agnostic Explanations)
LIME works by perturbing the inputs around a specific data point and observing how the model predictions change. It then trains a simple, inherently interpretable surrogate model, like a small decision tree or a linear classifier, on this new permuted dataset.
The surrogate model acts as an accurate local approximation of the complex deep learning network for that specific instance. LIME is highly adaptable and can be applied to text classification, tabular datasets, and image models without requiring direct access to the internal weights of the underlying network.
Gradient-Based Attribution and Integrated Gradients
For deep neural networks handling computer vision and natural language processing, gradient-based methods are frequently utilized. These techniques calculate the gradients of the output prediction with respect to the input features, effectively tracking how small alterations in individual pixels or words impact the final classification score.
Integrated Gradients solves a common limitation found in basic gradient approaches, known as gradient saturation, where important features show flat gradients because the model has already reached its maximum confidence level. By accumulating gradients along a linear path from a blank baseline input to the actual input instance, Integrated Gradients delivers highly accurate, pixel-level saliency maps that show exactly where a computer vision model focused its attention.
Enterprise Use Cases Across Key Industries
Implementing Explainable AI is not merely a theoretical exercise, it delivers measurable competitive advantages and mitigates operational risk across every major vertical adopting machine learning at scale.
Financial Services and Credit Risk Evaluation
In commercial banking, automated models regularly screen thousands of loan applications per minute. Regulatory bodies strictly mandate that financial institutions must be capable of providing clear, non-discriminatory reasons for adverse credit actions. By layering SHAP or LIME frameworks over deep gradient boosting or dense neural networks, risk management teams can instantly generate individual compliance statements for rejected applicants. This setup allows banks to leverage the superior predictive power of deep learning without sacrificing regulatory adherence.
Healthcare Diagnostics and Medical Imaging
Computer vision networks frequently outperform human radiologists in identifying early-stage anomalies in X-rays, MRIs, and CT scans. However, healthcare professionals cannot confidently prescribe invasive treatments based solely on an unexplained percentage score from an AI model. Utilizing Integrated Gradients and attention-mapping techniques allows the diagnostic platform to highlight the exact visual regions of interest on the medical image. The physician can then rapidly verify the biological anomalies flagged by the AI, blending machine precision with expert human oversight.
Autonomous Driving and Smart Logistics
Autonomous vehicles continuously interpret complex, multi-modal sensor arrays to make split-second driving choices. If an autonomous system executes a sudden evasive maneuver or an unexpected stop, engineering teams must immediately trace the underlying root cause. Integrating real-time attention visualization directly into the vehicle data logs allows development teams to determine if the system correctly recognized a hazard, or if it reacted erroneously to a benign environmental artifact, speeding up iterative development and improving safety protocols.
Strategic Blueprint for Implementing Explainable AI
Successfully deploying interpretability frameworks across an enterprise requires a deliberate, structured approach to data governance and software architecture.
1. Integrate XAI into the Core CI/CD Deployment Pipeline
Interpretability should never be treated as an afterthought or a manual reporting process executed at the end of the quarter. Explainability engines must be fully integrated directly into your automated machine learning deployment pipelines. Every time a new deep learning model version is trained and deployed, your system should automatically generate a standardized global explainability profile alongside standard precision and recall metrics.
2. Tailor Explanations to the Target Audience
An explanation that satisfies a senior software engineer will likely overwhelm a compliance auditor or an end customer. Your system architecture must be designed to present different levels of abstraction based on the specific user persona accessing the data.
Engineers require granular, pixel-level gradient paths and detailed feature impact weights to debug code effectively. Compliance officers need structured, clear text reports and aggregated fairness metrics that document model alignment with regulatory frameworks. End users require simple, intuitive summaries highlighting the top two or three actionable factors that influenced their personal experience.
3. Implement Continuous Model and Feature Drift Monitoring
Deep learning models are inherently dynamic entities whose real-world performance shifts over time as incoming data distributions evolve. By continuously tracking feature importance metrics in production, your engineering team can immediately identify when the model begins relying on secondary or unstable correlations to make predictions. A sudden shift in top feature attributions serves as an early warning indicator that a model requires retraining well before its overall accuracy metrics begin to degrade openly.
Conclusion
Explainable AI bridges the critical gap between high-performance computing and engineering accountability. By transforming deep learning from an opaque black box into a transparent, auditable asset, companies can confidently deploy advanced models within high-stakes operational environments. Embracing these interpretability frameworks minimizes systemic risk, streamlines regulatory compliance, and ensures that automated systems remain reliable, predictable, and fully aligned with your strategic enterprise objectives.
What Is Your Enterprise XAI Strategy?
How is your organization addressing the challenge of model opacity as you scale your deep learning deployments? Are you currently utilizing post-hoc frameworks like SHAP and LIME within your MLOps pipelines? Share your thoughts, strategies, and questions in the comments below, and subscribe to our newsletter to receive the latest technical insights delivered directly to your inbox.
Great content! Keep up the good work!