Have you ever wondered how AI systems can understand patterns in data without anyone labeling examples? Or how companies like Netflix and Spotify compress millions of images and audio files without losing the information that matters? The answer lies in one of the most elegant and powerful concepts in modern machine learning, autoencoders and their sophisticated cousin, variational autoencoders or VAEs.
Autoencoders represent a fundamental shift in how we approach problem solving with neural networks. Unlike supervised learning where we need labeled data, autoencoders work with raw data, discovering hidden patterns entirely on their own. In 2026, every machine learning engineer needs to understand autoencoders because they solve real problems that labeled datasets cannot address. They power generative AI, enable anomaly detection, drive content recommendation systems, and unlock insights from unlabeled data that companies have been sitting on for years.
This article will walk you through exactly how autoencoders work, why VAEs are different and more powerful, and how leading organizations are using them to extract value from data that previously seemed useless. By the end, you will understand why autoencoders are considered one of the most important unsupervised learning techniques. If you want to deepen your understanding of neural network architectures first, I recommend reading our previous article on Attention Mechanisms, which provides the foundation for understanding how modern AI systems process and learn from data.
The Problem: Why Labeled Data Kills Your AI Project Timeline
Before we discuss autoencoders, let me share why this technology became so critical in industry. Here is the hard truth that nobody talks about openly, labeled data is expensive and often impossible to obtain at scale.
Imagine you work at a manufacturing company. You have millions of sensor readings from equipment on the factory floor. You want your AI system to detect when a machine is about to fail so you can prevent costly downtime. But here is the problem, you do not have thousands of examples labeled as “machine failure” or “normal operation.” Those examples are rare and expensive to collect.
Or imagine you work at a healthcare company. You have millions of patient medical images, but you cannot label them all because that requires expensive radiologists to review every single scan. You cannot afford to build a supervised learning model.
Or consider security teams. They collect trillions of network logs and system events. But they cannot label every normal event versus every attack. The attack patterns change constantly, and new attacks emerge every day.
This is the fundamental problem that autoencoders solve. They learn from raw, unlabeled data. They do not care if you have labels. They do not care if your data is messy. They find patterns automatically.
What Exactly is an Autoencoder? The Simple Explanation
Let me explain autoencoders using an analogy that will click immediately.
Imagine you are a photographer trying to take the perfect selfie. Your goal is to capture what makes you uniquely you using the smallest possible file size. So you do not just save the original high resolution image. Instead, you compress it, removing unnecessary pixels and details, keeping only the essential information that represents your face.
That compressed version is called a bottleneck. It contains the core essence of your image. Then, when someone wants to see your full selfie, you decompress that bottleneck, reconstructing the original image from the compressed version.
An autoencoder works exactly the same way.
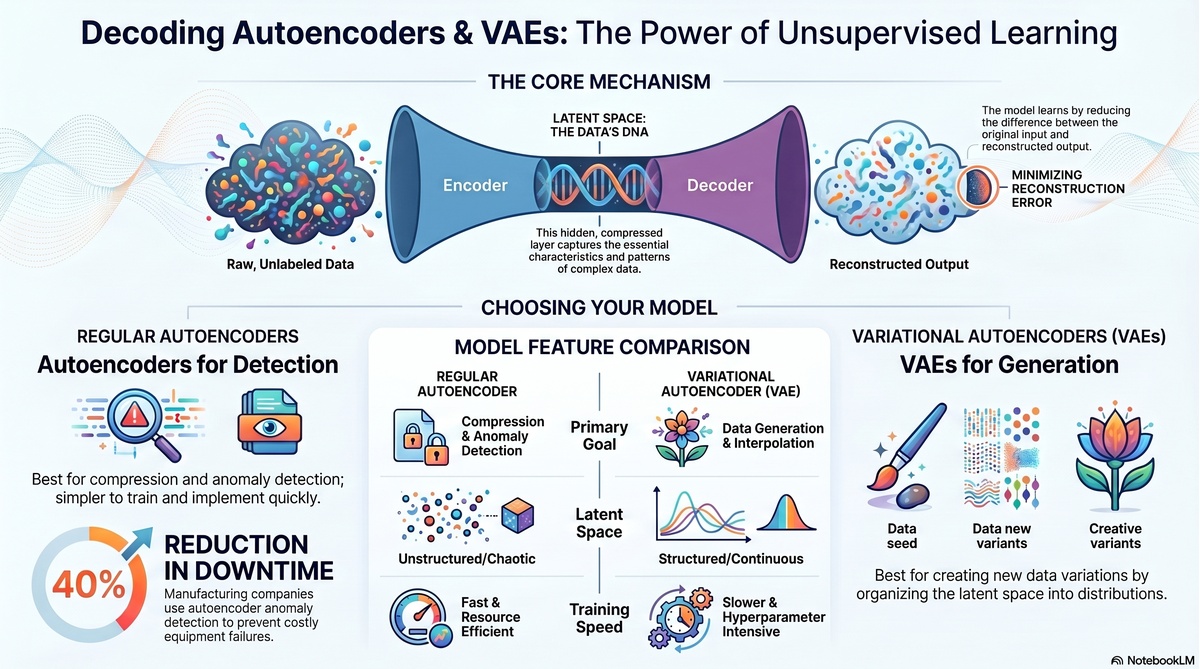
An autoencoder is a neural network that learns to compress data into a smaller representation and then reconstruct that data from the compressed version. The network has two main parts, an encoder that compresses input data into a bottleneck, and a decoder that reconstructs the original data from that bottleneck.
Here is what makes this powerful. During this process of encoding and decoding, the autoencoder learns the fundamental structure and patterns in your data. It learns what matters and what does not. It learns what variations are normal and what variations are anomalies. All without needing any labels.
The network learns this automatically because the goal is simple, make the reconstructed output match the original input as closely as possible. The difference between input and output is called the reconstruction error, and minimizing this error forces the autoencoder to learn meaningful representations.
The Architecture: How Autoencoders Actually Work
Let me walk you through a real example so you understand the architecture.
Imagine we are processing images of handwritten digits, like MNIST. Each image is 28 pixels by 28 pixels, which is 784 total pixels. This is our input data.
The encoder part of the autoencoder takes these 784 input values and compresses them step by step. Maybe the first layer goes from 784 inputs to 256 neurons. Then 256 to 128. Then 128 to 64. Then 64 to 32. Finally, it bottlenecks at just 8 neurons. Those 8 neurons contain the entire essence of the handwritten digit.
Then the decoder does the reverse. It takes those 8 neurons and expands them. 8 to 32 to 64 to 128 to 256, and finally back to 784 pixels, recreating the original image.
The magic happens in the bottleneck. Because the network is forced to fit all the important information into just 8 values, it learns which 8 characteristics matter most for reconstructing that digit. It learns things like, is the digit curved or angular? Is it tall or wide? Does it have loops? What is the general thickness?
This learned representation is incredibly useful. Companies use this bottleneck representation for clustering, for detecting anomalies, for generating new similar images, and for transfer learning. The compressed representation becomes a fingerprint of the data.
Understanding Latent Space: The Hidden Representation
Before we discuss the challenges with autoencoders, let me explain what latent space actually is because this concept is crucial to understanding both autoencoders and VAEs.
Latent space is the compressed, hidden representation of your data. It is the space where your data lives in its most compressed and abstract form. Think of it as the DNA of your data. Just like DNA contains all the information needed to recreate a person, latent space contains all the essential information needed to recreate your original data.
In our handwritten digit example, the latent space is those 8 neurons in the bottleneck. Those 8 numbers are not random, they encode specific characteristics about the digit. One neuron might represent curviness, another might represent height, another might represent thickness. The autoencoder automatically learned which 8 characteristics matter most for describing handwritten digits.
Here is the key insight, latent space lets you represent complex data using much simpler numbers. Your original image is 784 numbers, but the latent space captures its essence in just 8 numbers. This is incredibly powerful because it means you can:
- Compare data efficiently by comparing their latent space representations instead of comparing all 784 pixels
- Find anomalies easily by checking if a new data point’s reconstruction error is unusually high
- Generate new variations by moving around in latent space
- Transfer knowledge to other tasks by using the latent space as input to another model
The latent space is like a coordinate system where similar data points are close together and different data points are far apart. A digit 3 lives in one region of latent space, a digit 5 lives in another region, and different variations of digit 3 are all clustered together nearby.
The Problem with Regular Autoencoders: The Latent Space Issue
Now here is where it gets interesting and where VAEs come into play.
Regular autoencoders work well for compression and reconstruction, but they have a critical limitation. The bottleneck representation, called the latent space, becomes fragmented and chaotic. Different inputs get mapped to random positions in that latent space. There is no structure.
Think about it this way. You have eight values in your bottleneck. An image of the digit 3 might map to values like 0.2, 0.8, 0.1, 0.9, 0.3, 0.5, 0.7, 0.4. An image of the digit 5 might map to 0.9, 0.1, 0.6, 0.2, 0.8, 0.4, 0.1, 0.7. There is no logical structure connecting them.
This becomes a problem if you want to generate new data. If you randomly sample values from this chaotic latent space, you do not get meaningful images. You get garbage.
Companies tried anyway. They would take their autoencoders, sample random points in latent space, feed those through the decoder, and got nonsense. The latent space was not continuous. There were no meaningful transitions. Going from one region of the latent space to another did not create smooth variations of the data.
This is where variational autoencoders, or VAEs, revolutionized everything.
Variational Autoencoders: Adding Structure and Meaning
A VAE is a smarter version of an autoencoder that forces the latent space to have structure and organization.
Instead of encoding each input to a specific point in latent space, a VAE encodes each input to a probability distribution in latent space. Specifically, a normal distribution with a mean and a standard deviation.
Here is what this means in practice. When you encode an image of the digit 3, instead of getting eight specific values, you get eight means and eight standard deviations. The network is saying, this image of 3 belongs to a region of latent space centered around these means with this much variation.
During training, VAEs also add a clever constraint. They penalize the network if the learned distributions deviate too much from a standard normal distribution. Think of this as organizing chaos. Regular autoencoders create random scattered points in latent space, but VAEs force everything to cluster around zero with unit variance, like organizing a messy room so everything has a place. This constraint, called KL divergence, is what creates the magic. It ensures the entire latent space is populated with meaningful representations. If you sample anywhere in this organized space, you get valid data. The network learns to balance two goals, reconstruction accuracy and maintaining this organized structure. This balance is what makes VAEs so powerful for generation tasks.
What does this accomplish? Everything.
Now when you sample from the latent space, you get meaningful data because the entire space is populated with valid representations. There are no dead zones. Moving from one point to a nearby point in latent space produces smooth transitions in the reconstructed data. An image that is halfway between digit 3 and digit 5 in latent space produces an image that actually looks halfway between 3 and 5.
The latent space becomes continuous and structured. This is why VAEs revolutionized generative AI. Companies can now use VAEs to generate new variations of data, explore the space between different categories, and understand exactly what their AI models have learned about data structure.
When to Use Autoencoder vs VAE: A Practical Decision Guide
Now that you understand how both techniques work, the question becomes, which one should you use for your project? This decision significantly impacts your timeline, computational costs, and success likelihood.
Use a regular autoencoder if your primary goals are compression, dimensionality reduction, or anomaly detection. Autoencoders are simpler to implement, require fewer hyperparameters to tune, and train faster. If you are building a recommendation engine by encoding user behavior or detecting equipment failures by monitoring reconstruction error, a regular autoencoder is often sufficient and will get you to production faster.
Use a VAE if you need to generate new data, explore smooth interpolations between categories, or need a structured latent representation for downstream tasks. VAEs are more complex but unlock capabilities that regular autoencoders cannot provide. If you need your model to imagine new product designs, create variations of drug molecules, or interpolate between different data classes, VAE is your choice. Be prepared for more hyperparameter tuning and longer training times, but the results will justify the effort.
The key is asking yourself this question early, before you start coding, does my use case require generation or exploration of new data? If yes, choose VAE. If your focus is finding patterns, compressing data, or detecting anomalies, choose autoencoder. This simple question will save you months of wasted effort.
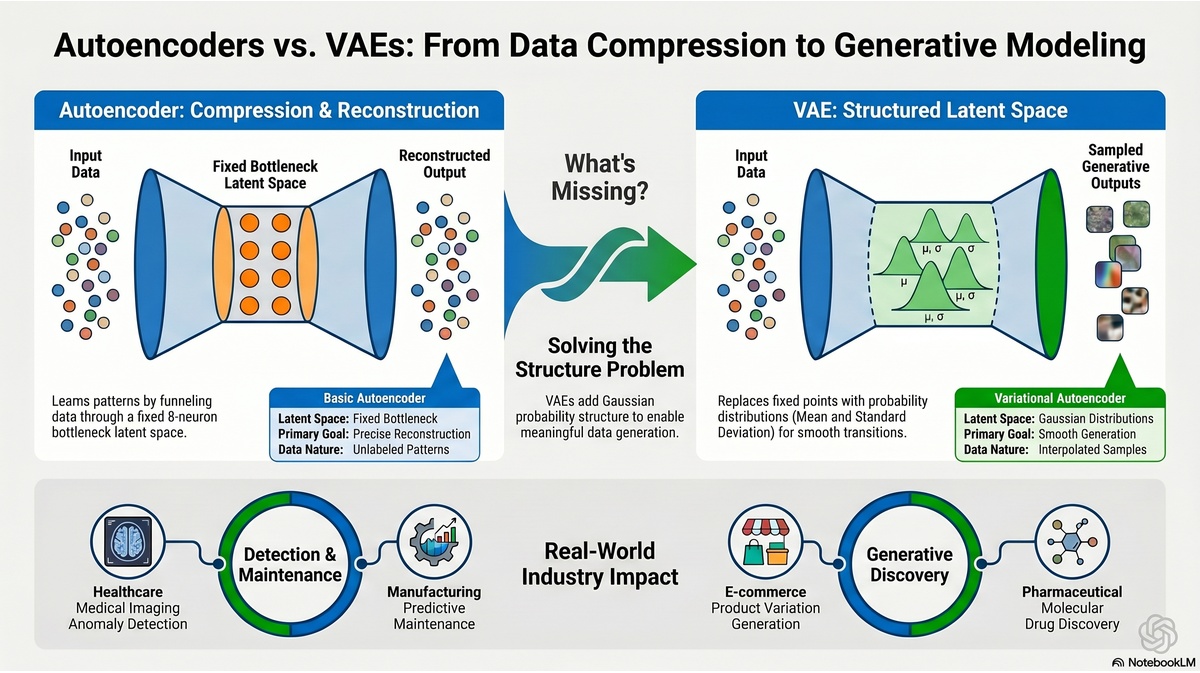
Visual comparison: Autoencoder vs VAE architecture and use cases
Real World Applications: Where Autoencoders and VAEs Make an Impact
Let me share how actual companies are using these techniques right now.
Netflix and other streaming companies use autoencoders for content recommendation. They encode user viewing patterns and show preferences into a compressed representation, then use similarity in that latent space to find customers with similar tastes. This is dramatically more efficient than comparing millions of raw preference dimensions and helps them reduce churn by 15-20%.
Healthcare companies use autoencoders for anomaly detection in medical imaging. They train an autoencoder on normal scans. If a scan has reconstruction error above a threshold, it signals something unusual that might need expert review. This helps radiologists prioritize their time on potentially problematic cases, reducing review time by 30% while improving diagnostic sensitivity.
Fashion and e-commerce companies use VAEs to generate new product variations. Train a VAE on existing products, sample the latent space, and the decoder produces novel product designs. This accelerates their design process by 40% and identifies market gaps they had not considered, directly impacting new product success rates.
Manufacturing companies use autoencoders for preventive maintenance. Train on normal equipment sensor data, then flag any equipment reading that has high reconstruction error as a potential failure signal. This prevents costly downtime, reducing unplanned maintenance incidents by 40% and saving millions annually in lost production.
Pharmaceutical companies use VAEs for drug discovery. They encode molecular structures into latent space, then explore that space to find molecules with desired properties. This is faster than testing millions of compounds physically, accelerating drug discovery timelines by 25-30% and reducing wet lab costs significantly.
The common thread across all these applications is the same. Companies have lots of unlabeled data. They need to find patterns, generate variations, or detect anomalies. Autoencoders and VAEs do exactly that, often delivering measurable ROI within months.
Common Mistakes: What Goes Wrong and How to Avoid It
After working with dozens of organizations implementing autoencoders, I have seen predictable mistakes that derail projects.
First mistake, using the wrong architecture for your bottleneck size. If your bottleneck is too small, your network cannot capture important information and produces low quality reconstructions. If your bottleneck is too large, the network cheats. It learns to almost directly pass the input through without extracting meaningful patterns. You need to tune this carefully with validation data.
Second mistake, not understanding when you actually need a VAE versus a regular autoencoder. If your goal is just compression or anomaly detection, regular autoencoders often work fine and are simpler. Only choose VAE if you specifically need a structured latent space for generation or exploration. VAEs have higher computational cost and more hyperparameters to tune.
Third mistake, ignoring the importance of the KL divergence term in VAE training. This is the term that forces the latent space to match a standard normal distribution. If you weight this incorrectly, you either get a chaotic latent space or a decoder that ignores the latent input entirely. This requires careful hyperparameter tuning.
Fourth mistake, not preprocessing your data appropriately. Autoencoders learn whatever patterns exist in raw data, including noise and artifacts. Clean your data. Normalize it. Remove outliers that do not represent real patterns. The quality of your input dramatically affects the quality of learned representations.
Fifth mistake, not having the right validation strategy. With autoencoders, you cannot use classification accuracy metrics. You need to track reconstruction error, latent space structure quality, and application specific metrics. Define what success looks like before you start training.
Key Takeaways: What You Need to Remember
Here is what you should take away from this article.
Autoencoders solve the critical problem of unsupervised learning at scale. When labeled data is expensive or unavailable, autoencoders discover patterns automatically.
Regular autoencoders excel at compression, anomaly detection, and dimensionality reduction. The bottleneck representation captures meaningful patterns in data.
Variational autoencoders add structured probability distributions to latent space, enabling generation of new data and smooth transitions between data variations.
The practical applications are enormous, from content recommendation to drug discovery to manufacturing anomaly detection. Every company with large unlabeled datasets should evaluate these techniques.
The key differentiator between good implementations and failed projects is understanding your specific goal and choosing the right autoencoder variant for that goal.
Now it is your turn. Do you have unlabeled data sitting in your organization? Do you need to generate variations of existing data? Could you benefit from detecting anomalies automatically? These are the questions to ask. Autoencoders and VAEs are proven technologies that work. The question is not whether they work, but whether your organization has the vision to apply them.
Challenge Yourself: Key Questions for Deep Understanding
Before moving forward, take a moment to reflect on these questions. They will test whether you truly understand the concepts and help you apply them to your own problems.
First, think about your organization. What large, unlabeled datasets do you have? Think beyond typical examples. Many companies have sensor data, user behavior logs, transaction records, or other data that nobody has bothered to label. Could autoencoder or VAE unlock value from that data?
Second, consider latent space organization. If you built a regular autoencoder on customer image data and wanted to generate new variations, what problem would you run into? Why would a VAE solve this problem? Understanding this deeply helps you make better architectural decisions.
Third, reflect on business impact. When a manufacturing company uses autoencoders to detect equipment failures before they happen, preventing 40% of downtime, what is the financial impact? How would you quantify and present this to your leadership? Learning to connect technical implementation to business outcomes is what separates successful AI projects from failed experiments.
These questions are not rhetorical. Spend time answering them. The answers will guide your implementation decisions.
Next Steps: From Theory to Implementation
If you want to dive deeper, start by exploring autoencoder implementations with popular libraries like PyTorch or TensorFlow. Begin with simple datasets like MNIST to build intuition, then progress to your own data.
For practitioners ready to implement autoencoders, experiment with Keras or scikit-learn for quick prototypes, then move to PyTorch for production systems. Start with supervised learning tasks to understand the fundamentals, then leverage autoencoders for unsupervised learning on your unlabeled data.
I recommend reading our comprehensive article on Attention Mechanisms if you want to understand how modern AI architectures compare and complement each other. This will give you a complete picture of neural network design patterns.
Getting Started: Tools, Libraries, and Resources
You do not need to build autoencoders from scratch. Excellent libraries make implementation straightforward.
For Python development, PyTorch and TensorFlow are industry standards. PyTorch is preferred for research and experimentation due to its dynamic computation graphs. TensorFlow is production-grade with excellent deployment options. For quick prototyping, scikit-learn offers simple autoencoders without deep learning complexity.
For visualization and monitoring, TensorBoard helps you understand what your latent space is learning. Weights and Biases (wandb) provides experiment tracking and hyperparameter visualization, invaluable for tuning VAEs.
For learning resources, start with Fast.ai courses on autoencoders, which focus on practical implementation. StatQuest on YouTube provides intuitive explanations of complex concepts. Hugging Face has pre-trained models and tutorials for generative tasks.
For AI Engineers and Data Scientists
I recommend this practical approach:
1. Implement a simple autoencoder on MNIST to understand the bottleneck concept
2. Experiment with VAEs to see how structured latent space enables generation
3. Apply autoencoders to your own unlabeled data for anomaly detection
4. Build a small proof of concept for your organization’s data challenges
For leaders and decision makers, evaluate whether autoencoders solve your data challenges. Many organizations sit on goldmines of unlabeled data that could unlock competitive advantages if properly analyzed.
If you found this article valuable, share it with your team. Subscribe for more insights on unsupervised learning, deep learning, and practical AI architecture patterns. Drop a comment below with your questions about autoencoders, VAEs, or your experiences building unsupervised learning systems. I would love to hear from you about how you are using these concepts in your organization.