Have you ever wondered how ChatGPT understands context so perfectly? Or how Google Translate produces such natural translations across 100 languages? The answer lies in a single, elegant concept that revolutionized artificial intelligence over the past five years, attention mechanisms.
Understanding attention mechanisms is no longer optional for AI professionals, machine learning engineers, or anyone building intelligent systems. In 2026, if you do not understand how attention works, you are missing the fundamental architecture behind every major AI breakthrough from GPT-4 to Claude to BERT.
This article will walk you through exactly how attention mechanisms function, why they matter for your organization, and how they connect to the broader AI landscape we covered in our previous article on transfer learning. By the end, you will have a clear understanding of why tech giants invest billions in transformer-based models and how you can leverage this knowledge in your projects.
The Problem Before Attention: Why Companies Failed with Early AI
Before we discuss what attention mechanisms are, let me share why companies struggled with older approaches. In the early 2010s, when deep learning was just gaining traction, major tech companies built neural networks using recurrent neural networks, or RNNs. These models processed information sequentially, one token at a time.
Sounds simple, right? It was not. Here is what happened in practice.
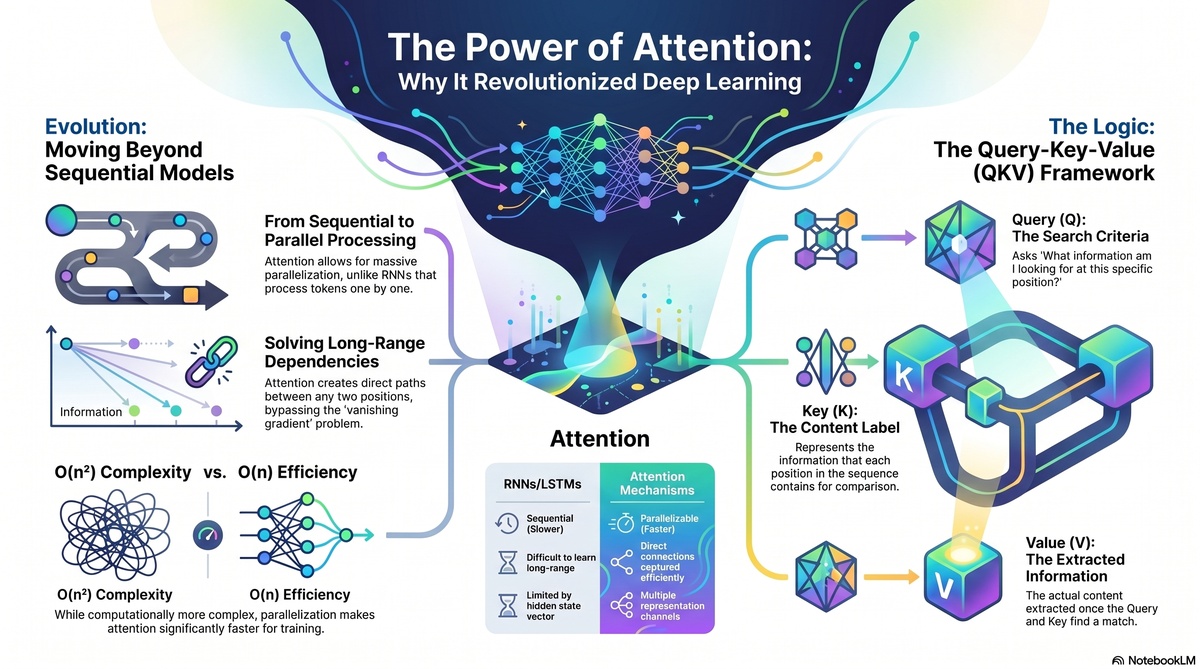
When a model tried to understand a 100 word paragraph, it had to process word 1, then word 2, then word 3, and so on. This meant processing was slow, parallelization was impossible, and long documents would lose meaning by the time the model reached the end. We call this the vanishing gradient problem, a phenomenon where information simply evaporates as it travels through many layers.
Think of it like a game of telephone. When you whisper a message through 100 people, the last person understands almost nothing. RNNs had the same problem.
By 2016 and 2017, companies like Google, Facebook, and OpenAI were looking for solutions. They needed models that could handle long sequences, train faster, and actually remember important information over long distances. That is when attention mechanisms entered the picture.
What Exactly is Attention? The Human Brain Analogy
Let me explain attention using something you do every single day without thinking about it.
Right now, you are reading this article. But notice what your brain is doing. You are not paying equal attention to every word. You are focusing intensely on words that matter for understanding, words like attention, mechanisms, and neural networks. You are skimming over articles, prepositions, and filler words. Your attention is selective and dynamic.
Attention mechanisms in AI work exactly the same way.
An attention mechanism is a neural network component that allows models to focus on specific parts of input data while processing information. Instead of treating all input equally, it assigns different importance weights to different elements based on their relevance to the current task.
Here is the key insight that changed everything: if we give AI models the ability to decide what to focus on, they perform dramatically better. Not just marginally better, but orders of magnitude better.
How Does Attention Actually Work? The Mechanism Explained
I know you want the technical details, but I am going to explain this without formulas because the concept matters more than the mathematics.
At its core, attention works by answering three questions for every piece of input:
- What am I looking for right now? This is called the query. It represents what the model is trying to find or what it cares about at this moment.
- What information is available in my input? This is called the key. Each element in the input gets a key that describes what information it contains.
- What information should I actually extract? This is called the value. The value represents the actual information we want to use.
Let me use a real example. Imagine translating the sentence “The cat sat on the mat” to another language.
When the model processes the word cat, it asks three questions:
– Query: What information do I need about the subject of this sentence?
– Keys: What does each word tell me about subjects?
– Values: What information should I extract from each word?
The model then evaluates each word. The word cat has a key that says this is a noun and the subject. The word the has a key that says this is an article. The word sat has a key that says this is a verb. The model assigns higher attention to cat because its key matches the query for subject information.
This is elegant. By using queries, keys, and values, the model learns to automatically focus on what matters without us programming it explicitly.
Multi Head Attention: The Game Changer
Now here is where it gets really interesting and why attention became so powerful.
A single attention head can only learn one type of relationship at a time. One head might learn to focus on subject verb relationships. Another might learn to focus on adjectives. A third might capture long range dependencies.
What if we use multiple attention heads working in parallel? This is called multi head attention. It means the model runs multiple independent attention operations simultaneously, each learning different patterns, then combines all the results.
This was revolutionary. Imagine having 12 experts looking at the same data simultaneously. Expert 1 specializes in grammar relationships. Expert 2 specializes in semantic meaning. Expert 3 specializes in entity relationships. Expert 4 through 12 each find other important patterns. Then all 12 experts share their findings.
This is why modern AI models use 8 to 12 attention heads. Each head contributes unique insights, and together they create incredibly rich representations of the data.
The Transformer Architecture: From Theory to Practice
In 2017, researchers at Google published a paper titled Attention is All You Need. This paper introduced the transformer architecture, and it fundamentally changed AI.
The key breakthrough was this: we do not need recurrence at all. We do not need to process sequences one item at a time. If we use attention mechanisms cleverly, we can process entire sequences in parallel.
Here is why this matters for your organization or your career. Parallel processing meant:
- Training that took days now took hours
- Models could handle longer documents
- Multiple GPUs and TPUs could work together efficiently
- We could build larger models with more parameters
The transformer architecture combines several components. Multi head attention handles relationships between different parts of your data. Feed forward networks add non linearity and transform information. Layer normalization stabilizes training. Positional encoding tells the model where each element sits in the sequence because attention alone does not understand word order.
When you combine all these pieces, you get an architecture that can be scaled up to hundreds of billions of parameters while maintaining stable training and understanding.
Why Attention Matters for Every AI Practitioner
Let me be direct about why you should care about attention mechanisms.
Today, 99 percent of state of the art AI systems use attention. Language models like GPT-4, Claude, Gemini, and Llama all use transformers with attention. Vision systems use vision transformers. Speech systems use attention. Multimodal AI that combines text, images, and video uses attention.
This is not a niche technique anymore. This is the foundation of modern AI.
For executives, this means understanding attention helps you evaluate AI vendors and capabilities. When someone pitches you an AI solution, you can ask intelligent questions about their architecture. You can understand why transformer based systems perform so well.
For engineers, mastery of attention mechanisms unlocks access to cutting edge AI work. Companies building LLMs, working on multimodal AI, developing speech systems, and creating computer vision applications all prioritize people who deeply understand transformers.
Real World Applications: Where Attention Changed Everything
Natural language processing saw the biggest transformation. Translation systems went from producing awkward sentences to translations that humans cannot distinguish from native speakers. Question answering systems can now find relevant information in documents and synthesize accurate answers. Sentiment analysis identifies which words influenced a decision, making models interpretable.
In computer vision, vision transformers now match or exceed the performance of traditional convolutional neural networks. Object detection no longer requires hand crafted algorithms. Image classification can be done end to end with learned attention patterns.
Multimodal systems combine text and images using cross attention. Image captioning systems look at specific image regions while generating descriptions. Visual question answering systems understand questions and attend to relevant image regions to answer accurately.
Speech and audio applications use attention to align audio frames with text. Text to speech systems attend to text while generating natural sounding speech. These systems produce results that sound almost human.
Connecting to Transfer Learning: The Bigger Picture
In our previous article on transfer learning for natural language processing, we discussed how training large models on general data then fine tuning them for specific tasks creates incredibly capable systems. Attention mechanisms are the architectural foundation that makes transfer learning possible.
BERT, GPT, and similar models work because their transformer architecture with attention can learn general language patterns from massive datasets. Then organizations fine tune these models for specific tasks with relatively small amounts of labeled data.
This means that understanding attention helps you understand transfer learning better. They work together. Attention provides the architectural capability. Transfer learning provides the training strategy. Together, they create the AI systems that power industry today.
Why Companies Are Investing Billions in Attention
If you follow AI news, you have noticed massive investments in large language models. OpenAI has received $10 billion from Microsoft. Google continues investing heavily in Gemini and similar models. Meta, Amazon, and every major tech company is building transformer based systems.
Why? Because attention mechanisms fundamentally work. The empirical results speak for themselves.
According to recent benchmarks from 2025 and 2026, transformer models outperform traditional approaches on nearly every metric. Training time is shorter despite model sizes being larger. Accuracy is higher. Models generalize better to new domains. Interpretability is better because we can visualize what the model attends to.
This is not just academic success. Companies are building billion dollar products on transformer architectures. Every major cloud provider offers transformer inference as a service. Consulting firms specialize in fine tuning transformers for enterprise applications.
Practical Considerations for Building with Attention
If you are building AI systems with attention mechanisms, here are key practical insights.
First, training stability matters. Attention mechanisms can be unstable during early training if you are not careful. Starting with a small learning rate and gradually increasing it prevents initial divergence. Carefully initializing weights using Xavier or He initialization prevents saturation. Gradient clipping prevents exploding gradients in deep models.
Second, understand the computational cost. Attention scales as the square of sequence length. This means doubling your sequence length quadruples your computation. For text that is fine. For very long documents or video, you may need efficient variants like FlashAttention or sparse attention patterns.
Third, positional information matters. Attention alone does not understand that word order matters. The difference between I love you and you love me is not visible to pure attention. This is why we add positional encodings that tell the model where each element sits in the sequence.
Fourth, multiple heads work better than single heads. Eight to twelve heads is standard. More heads shows diminishing returns. Fewer heads hurts performance significantly.
Common Mistakes to Avoid
Forgetting positional information is the most common mistake. Without it, models fail to understand sequences correctly.
Ignoring computational complexity leads to resource problems. Some organizations build systems that work on small test sets then fail in production because they did not account for the squared complexity with sequence length.
Over engineering the architecture hurts more than it helps. Using 64 attention heads or 96 transformer layers rarely beats a simpler 12 head, 24 layer model because computational budgets are limited. Better to be wider than deeper.
Assuming pre trained models work without fine tuning is another mistake. While transfer learning is powerful, you almost always need to adapt models to your specific domain and task.
The Future of Attention Mechanisms
We are seeing interesting developments in 2026. Efficient attention variants like FlashAttention enable processing much longer sequences. Sparse attention focuses on nearby tokens rather than all tokens, reducing computation dramatically. Linear attention approximates attention patterns with linear complexity.
Multi modal attention is combining text, images, video, and audio seamlessly. We are moving toward truly unified AI systems that understand multiple input types simultaneously.
Context windows are growing. Early transformers handled 1000 tokens. Modern systems handle 100,000 tokens. Research is pushing toward million token context windows, enabling analysis of entire codebases or books at once.
These advances build on the fundamental attention mechanism but push its capabilities further. Understanding the basics positions you to understand these advances.
Key Takeaways and Action Items
Let me summarize the core insights about attention mechanisms:
Attention allows models to selectively focus on relevant information instead of treating all inputs equally. This solved the long range dependency problem that plagued earlier neural networks. Multi head attention enables models to learn multiple relationship types in parallel, dramatically improving expressiveness. The transformer architecture, built on attention, became the foundation for state of the art AI systems across NLP, vision, speech, and multimodal domains. Understanding attention is essential for AI professionals, engineers, and leaders evaluating AI solutions.
For executives, evaluate potential AI vendors based on their understanding of transformer architectures. For engineers, deepen your understanding of attention mechanisms because it opens doors to cutting edge work.
Your Next Steps
I recommend diving deeper into transformer architectures. Read the original Attention is All You Need paper to understand the full details. Implement a simple attention mechanism from scratch to build intuition about how it works.
Experiment with pre trained transformer models using Hugging Face. Fine tune BERT or similar models on your data to see transfer learning in action. Build practical experience with these systems because that is how you truly master the concepts.
If you found this article valuable, please share it with your team and colleagues. Subscribe to our newsletter for more insights on AI architecture and deep learning. Drop a comment below with your questions about attention mechanisms or your experiences building transformer based systems.
I would love to hear from you about how you are using these concepts in your organization.